Refine search
Actions for selected content:
18 results
Numeric vs. Natural Language Messages in Experimental Cheap Talk Games
-
- Journal:
- Journal of the Economic Science Association ,
- Published online by Cambridge University Press:
- 31 July 2025, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Classification of natural language messages using a coordination game
-
- Journal:
- Experimental Economics / Volume 14 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 March 2025, pp. 1-14
-
- Article
- Export citation
How the Laws of Logic Lie
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
22 - Narrative and Natural Language
- from VII - Finale
-
-
- Book:
- Narrative Science
- Published online:
- 16 September 2022
- Print publication:
- 06 October 2022, pp 447-464
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Is Aristotle the Forefather of Informal Logic?
-
- Journal:
- Dialogue: Canadian Philosophical Review / Revue canadienne de philosophie / Volume 61 / Issue 1 / April 2022
- Published online by Cambridge University Press:
- 10 June 2021, pp. 139-159
-
- Article
-
- You have access
- HTML
- Export citation
17 - Computational Linguistics
- from Part 8 - Brief Chapters on the Companion Website
-
-
- Book:
- Introducing Linguistics
- Published online:
- 22 April 2021
- Print publication:
- 21 January 2021, pp 581-592
-
- Chapter
- Export citation
7 - On the Side of Natural Language
-
- Book:
- Gödel, Tarski and the Lure of Natural Language
- Published online:
- 03 December 2020
- Print publication:
- 17 December 2020, pp 159-168
-
- Chapter
- Export citation
Reid on the priority of natural language
-
- Journal:
- Canadian Journal of Philosophy / Volume 41 / Issue S1 / July 2011
- Published online by Cambridge University Press:
- 01 January 2020, pp. 214-223
-
- Article
- Export citation
Enhancing Environmental Engagement with Natural Language Interfaces for In-Vehicle Navigation Systems
-
- Journal:
- The Journal of Navigation / Volume 72 / Issue 3 / May 2019
- Published online by Cambridge University Press:
- 15 February 2019, pp. 513-527
- Print publication:
- May 2019
-
- Article
- Export citation
LOGICS FOR PROPOSITIONAL DETERMINACY AND INDEPENDENCE
-
- Journal:
- The Review of Symbolic Logic / Volume 11 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 02 April 2018, pp. 470-506
- Print publication:
- September 2018
-
- Article
- Export citation
-
This paper investigates formal logics for reasoning about determinacy and independence. Propositional Dependence Logic
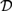 ${\cal D}$ and Propositional Independence Logic
${\cal D}$ and Propositional Independence Logic 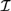 ${\cal I}$ are recently developed logical systems, based on team semantics, that provide a framework for such reasoning tasks. We introduce two new logics
${\cal I}$ are recently developed logical systems, based on team semantics, that provide a framework for such reasoning tasks. We introduce two new logics 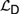 ${{\cal L}_D}$ and
${{\cal L}_D}$ and 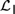 ${{\cal L}_{\,I\,}}$, based on Kripke semantics, and propose them as alternatives for
${{\cal L}_{\,I\,}}$, based on Kripke semantics, and propose them as alternatives for 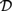 ${\cal D}$ and
${\cal D}$ and  ${\cal I}$, respectively. We analyse the relative expressive powers of these four logics and discuss the way these systems relate to natural language. We argue that
${\cal I}$, respectively. We analyse the relative expressive powers of these four logics and discuss the way these systems relate to natural language. We argue that 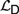 ${{\cal L}_D}$ and
${{\cal L}_D}$ and 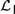 ${{\cal L}_{\,I\,}}$ naturally resolve a range of interpretational problems that arise in
${{\cal L}_{\,I\,}}$ naturally resolve a range of interpretational problems that arise in 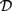 ${\cal D}$ and
${\cal D}$ and 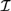 ${\cal I}$. We also obtain sound and complete axiomatizations for
${\cal I}$. We also obtain sound and complete axiomatizations for 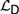 ${{\cal L}_D}$ and
${{\cal L}_D}$ and 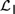 ${{\cal L}_{\,I\,}}$.
${{\cal L}_{\,I\,}}$.
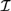
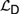
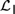
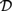

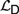
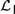
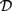
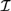
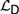
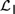
A THREE-VALUED QUANTIFIED ARGUMENT CALCULUS: DOMAIN-FREE MODEL-THEORY, COMPLETENESS, AND EMBEDDING OF FOL
-
- Journal:
- The Review of Symbolic Logic / Volume 10 / Issue 3 / September 2017
- Published online by Cambridge University Press:
- 08 May 2017, pp. 549-582
- Print publication:
- September 2017
-
- Article
- Export citation
An application of answer set programming to the field of second language acquisition
-
- Journal:
- Theory and Practice of Logic Programming / Volume 15 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 22 January 2014, pp. 1-17
-
- Article
- Export citation
25 - Parameters: the pluses and the minuses
- from Part VI - Syntax and the external interfaces
-
-
- Book:
- The Cambridge Handbook of Generative Syntax
- Published online:
- 05 August 2013
- Print publication:
- 25 July 2013, pp 927-970
-
- Chapter
- Export citation
20 - Tense, aspect, and modality
- from Part V - Syntax and the internal interfaces
-
-
- Book:
- The Cambridge Handbook of Generative Syntax
- Published online:
- 05 August 2013
- Print publication:
- 25 July 2013, pp 746-792
-
- Chapter
- Export citation
Chapter 3 - Existence and quantification reconsidered
-
-
- Book:
- Contemporary Aristotelian Metaphysics
- Published online:
- 05 December 2011
- Print publication:
- 08 December 2011, pp 44-65
-
- Chapter
- Export citation
4 - Systematicity and intentional realism in honeybee navigation
-
-
- Book:
- The Philosophy of Animal Minds
- Published online:
- 05 June 2012
- Print publication:
- 03 September 2009, pp 72-88
-
- Chapter
- Export citation
Observations psychiatriques en langage naturel, statistique textuelle et classification des dépressions
-
- Journal:
- Psychiatry and Psychobiology / Volume 5 / Issue 1 / 1990
- Published online by Cambridge University Press:
- 28 April 2020, pp. 1-11
- Print publication:
- 1990
-
- Article
- Export citation
