Refine search
Actions for selected content:
60 results
A multivariate spatiotemporal model for county-level mortality data in the contiguous United States
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 11 August 2025, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hierarchical Gaussian processes for characterizing gait variability in multiple sclerosis
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 07 August 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Negative moments of the CREM partition function in the high-temperature regime
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 29 July 2025, pp. 1623-1641
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The continuous random energy model (CREM) was introduced by Bovier and Kurkova in 2004 as a toy model of disordered systems. Among other things, their work indicates that there exists a critical point
 $\beta_\mathrm{c}$ such that the partition function exhibits a phase transition. The present work focuses on the high-temperature regime where
$\beta_\mathrm{c}$ such that the partition function exhibits a phase transition. The present work focuses on the high-temperature regime where  $\beta<\beta_\mathrm{c}$. We show that, for all
$\beta<\beta_\mathrm{c}$. We show that, for all  $\beta<\beta_\mathrm{c}$ and for all
$\beta<\beta_\mathrm{c}$ and for all  $s>0$, the negative s moment of the CREM partition function is comparable with the expectation of the CREM partition function to the power of
$s>0$, the negative s moment of the CREM partition function is comparable with the expectation of the CREM partition function to the power of  $-s$, up to constants that are independent of N.
$-s$, up to constants that are independent of N.





4 - Gaussian processes and other kernel methods
-
- Book:
- Machine Learning in Quantum Sciences
- Published online:
- 13 June 2025
- Print publication:
- 12 June 2025, pp 76-110
-
- Chapter
- Export citation
6 - Regression Models
- from Part II - Statistical Models
-
- Book:
- Data Modeling for the Sciences
- Published online:
- 17 August 2023
- Print publication:
- 31 August 2023, pp 215-244
-
- Chapter
- Export citation
2 - Emerging Directions in Geophysical Inversion
- from Part I - Introduction
-
-
- Book:
- Applications of Data Assimilation and Inverse Problems in the Earth Sciences
- Published online:
- 20 June 2023
- Print publication:
- 06 July 2023, pp 9-26
-
- Chapter
- Export citation
Exploration-exploitation-based trajectory tracking of mobile robots using Gaussian processes and model predictive control
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
13 - Kernel Methods
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 440-472
-
- Chapter
- Export citation
A dependent multimodel approach to climate prediction with Gaussian processes
- Part of
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 05 December 2022, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Virtual sensing in an onshore wind turbine tower using a Gaussian process latent force model
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 28 November 2022, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predicting spatiotemporal variability in radial tree growth at the continental scale with machine learning
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 22 June 2022, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiphase flow applications of nonintrusive reduced-order models with Gaussian process emulation
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 16 May 2022, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Design of monopole antennas based on progressive Gaussian process
-
- Journal:
- International Journal of Microwave and Wireless Technologies / Volume 15 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 07 March 2022, pp. 255-262
-
- Article
- Export citation
Extrema of multi-dimensional Gaussian processes over random intervals
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 28 February 2022, pp. 81-104
- Print publication:
- March 2022
-
- Article
- Export citation
-
This paper studies the joint tail asymptotics of extrema of the multi-dimensional Gaussian process over random intervals defined as
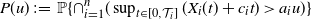 $P(u)\;:\!=\; \mathbb{P}\{\cap_{i=1}^n (\sup_{t\in[0,\mathcal{T}_i]} ( X_{i}(t) +c_i t )>a_i u )\}$,
$P(u)\;:\!=\; \mathbb{P}\{\cap_{i=1}^n (\sup_{t\in[0,\mathcal{T}_i]} ( X_{i}(t) +c_i t )>a_i u )\}$, 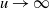 $u\rightarrow\infty$, where
$u\rightarrow\infty$, where 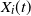 $X_i(t)$,
$X_i(t)$, 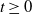 $t\ge0$,
$t\ge0$, 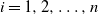 $i=1,2,\ldots,n$, are independent centered Gaussian processes with stationary increments,
$i=1,2,\ldots,n$, are independent centered Gaussian processes with stationary increments, 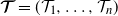 $\boldsymbol{\mathcal{T}}=(\mathcal{T}_1, \ldots, \mathcal{T}_n)$ is a regularly varying random vector with positive components, which is independent of the Gaussian processes, and
$\boldsymbol{\mathcal{T}}=(\mathcal{T}_1, \ldots, \mathcal{T}_n)$ is a regularly varying random vector with positive components, which is independent of the Gaussian processes, and 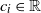 $c_i\in \mathbb{R}$,
$c_i\in \mathbb{R}$, 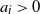 $a_i>0$,
$a_i>0$, 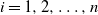 $i=1,2,\ldots,n$. Our result shows that the structure of the asymptotics of P(u) is determined by the signs of the drifts
$i=1,2,\ldots,n$. Our result shows that the structure of the asymptotics of P(u) is determined by the signs of the drifts 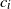 $c_i$. We also discuss a relevant multi-dimensional regenerative model and derive the corresponding ruin probability.
$c_i$. We also discuss a relevant multi-dimensional regenerative model and derive the corresponding ruin probability.
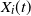
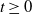
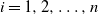
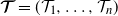
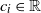
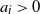
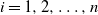
Polls, Context, and Time: A Dynamic Hierarchical Bayesian Forecasting Model for US Senate Elections
-
- Journal:
- Political Analysis / Volume 31 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 18 January 2022, pp. 113-133
-
- Article
- Export citation
11 - Time- and Space-Variant Reliability Analysis
-
- Book:
- Structural and System Reliability
- Published online:
- 13 January 2022
- Print publication:
- 13 January 2022, pp 357-404
-
- Chapter
- Export citation
13 - Reliability Methods for Stochastic Structural Dynamics
-
- Book:
- Structural and System Reliability
- Published online:
- 13 January 2022
- Print publication:
- 13 January 2022, pp 446-492
-
- Chapter
- Export citation
Asymptotic behavior of the weak approximation to a class of Gaussian processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 693-707
- Print publication:
- September 2021
-
- Article
- Export citation
Multi-output Gaussian processes for multi-population longevity modelling
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 2 / July 2021
- Published online by Cambridge University Press:
- 17 May 2021, pp. 318-345
-
- Article
- Export citation
