Refine search
Actions for selected content:
22 results
Large and moderate deviations for Gaussian neural networks
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 01 October 2025, pp. 1-20
-
- Article
- Export citation
Smoothness and monotonicity constraints for neural networks using ICEnet
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 3 / November 2024
- Published online by Cambridge University Press:
- 01 April 2024, pp. 712-739
-
- Article
- Export citation
On the Opacity of Deep Neural Networks
-
- Journal:
- Canadian Journal of Philosophy / Volume 53 / Issue 3 / April 2023
- Published online by Cambridge University Press:
- 25 March 2024, pp. 224-239
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - Formalizing Deep Neural Networks
- from Part I - Theory of Deep Learning for Image Reconstruction
-
-
- Book:
- Deep Learning for Biomedical Image Reconstruction
- Published online:
- 15 September 2023
- Print publication:
- 12 October 2023, pp 3-12
-
- Chapter
- Export citation
Climate model-driven seasonal forecasting approach with deep learning
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 26 July 2023, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Understanding seasonal climatic conditions is critical for better management of resources such as water, energy, and agriculture. Recently, there has been a great interest in utilizing the power of Artificial Intelligence (AI) methods in climate studies. This paper presents cutting-edge deep-learning models (UNet++, ResNet, PSPNet, and DeepLabv3) trained by state-of-the-art global CMIP6 models to forecast global temperatures a month ahead using the ERA5 reanalysis dataset. ERA5 dataset was also used for fine-tuning as well performance analysis in the validation dataset. Ten different setups (with CMIP6 and CMIP6 + ERA5 fine-tuning) including six meteorological parameters (i.e., 2 m temperature, 10 m eastward component of wind, 10 m northward component of wind, geopotential height at 500 hPa, mean sea-level pressure, and precipitation flux) and elevation were used with both four different algorithms. For each model 14 different sequential and nonsequential temporal settings were used. The mean absolute error (MAE) analysis revealed that UNet++ with CMIP6 with 2 m temperature + elevation and ERA5 fine-tuning model with “Year 3 Month 2” temporal case provided the best outcome with an MAE of 0.7. Regression analysis over the validation dataset between the ERA5 data values and the corresponding AI model predictions revealed slope and
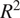 $ {R}^2 $ values close to 1 suggesting a very good agreement. The AI model predicts significantly better than the mean CMIP6 ensemble between 2016 and 2021. Both models predict the summer months more accurately than the winter months.
$ {R}^2 $ values close to 1 suggesting a very good agreement. The AI model predicts significantly better than the mean CMIP6 ensemble between 2016 and 2021. Both models predict the summer months more accurately than the winter months.
34 - Modeling Vision
- from Part IV - Computational Modeling in Various Cognitive Fields
-
-
- Book:
- The Cambridge Handbook of Computational Cognitive Sciences
- Published online:
- 21 April 2023
- Print publication:
- 11 May 2023, pp 1113-1134
-
- Chapter
- Export citation
2 - Connectionist Models of Cognition
- from Part II - Cognitive Modeling Paradigms
-
-
- Book:
- The Cambridge Handbook of Computational Cognitive Sciences
- Published online:
- 21 April 2023
- Print publication:
- 11 May 2023, pp 29-79
-
- Chapter
- Export citation
FUZZY APPROACHES AGAINST OUTLIERS AND APPLICATIONS IN WIND ENERGY
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 107 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 03 February 2023, pp. 346-348
- Print publication:
- April 2023
-
- Article
-
- You have access
- HTML
- Export citation
Deep problems with neural network models of human vision
-
- Journal:
- Behavioral and Brain Sciences / Volume 46 / 2023
- Published online by Cambridge University Press:
- 01 December 2022, e385
-
- Article
-
- You have access
- HTML
- Export citation
19 - Automatic Speech Recognition by Machines
- from Section IV - Audition and Perception
-
-
- Book:
- The Cambridge Handbook of Phonetics
- Published online:
- 11 November 2021
- Print publication:
- 02 December 2021, pp 480-500
-
- Chapter
- Export citation
Assurance monitoring of learning-enabled cyber-physical systems using inductive conformal prediction based on distance learning
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prediction of aircraft estimated time of arrival using machine learning methods
-
- Journal:
- The Aeronautical Journal / Volume 125 / Issue 1289 / July 2021
- Published online by Cambridge University Press:
- 17 March 2021, pp. 1245-1259
-
- Article
- Export citation
Automatic analysis of insurance reports through deep neural networks to identify severe claims
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 09 March 2021, pp. 42-67
-
- Article
- Export citation
Generation of geometric interpolations of building types with deep variational autoencoders
- Part of
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 28 December 2020, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Motion Adaptation Based on Learning the Manifold of Task and Dynamic Movement Primitive Parameters
-
- Article
-
- You have access
- Open access
- Export citation
Deep learning models for global coordinate transformations that linearise PDEs
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 32 / Issue 3 / June 2021
- Published online by Cambridge University Press:
- 24 September 2020, pp. 515-539
-
- Article
- Export citation
Theoretical analysis of skip connections and batch normalization from generalization and optimization perspectives
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 27 February 2020, e9
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Galaxy Classifications with Deep Learning
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 12 / Issue S325 / October 2016
- Published online by Cambridge University Press:
- 30 May 2017, pp. 217-220
- Print publication:
- October 2016
-
- Article
-
- You have access
- Export citation
