Refine search
Actions for selected content:
143 results

Foundations of MATLAB Programming for Behavioral Sciences
- With Applications
- Coming soon
-
- Expected online publication date:
- September 2025
- Print publication:
- 07 August 2025
-
- Textbook
- Export citation

Probability Theory for Quantitative Scientists
-
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025
Session-effects in the laboratory
-
- Journal:
- Experimental Economics / Volume 15 / Issue 3 / September 2012
- Published online by Cambridge University Press:
- 14 March 2025, pp. 485-498
-
- Article
- Export citation
Impact of seismic activities on the optical synchronization system of the European X-ray Free-Electron Laser
-
- Journal:
- High Power Laser Science and Engineering / Volume 13 / 2025
- Published online by Cambridge University Press:
- 05 March 2025, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
WALLABY Pilot Survey: HI source-finding with a machine learning framework
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e033
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The data volumes generated by theWidefield ASKAP L-band Legacy All-sky Blind surveY atomic hydrogen (Hi) survey using the Australian Square Kilometre Array Pathfinder (ASKAP) necessitate greater automation and reliable automation in the task of source finding and cataloguing. To this end, we introduce and explore a novel deep learning framework for detecting low signal-to-noise ratio (SNR) Hi sources in an automated fashion. Specifically, our proposed method provides an automated process for separating true Hi detections from false positives when used in combination with the source finding application output candidate catalogues. Leveraging the spatial and depth capabilities of 3D convolutional neural networks, our method is specifically designed to recognize patterns and features in three-dimensional space, making it uniquely suited for rejecting false-positive sources in low SNR scenarios generated by conventional linear methods. As a result, our approach is significantly more accurate in source detection and results in considerably fewer false detections compared to previous linear statistics-based source finding algorithms. Performance tests using mock galaxies injected into real ASKAP data cubes reveal our method’s capability to achieve near-100% completeness and reliability at a relatively low integrated SNR
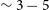 $\sim3-5$. An at-scale version of this tool will greatly maximise the science output from the upcoming widefield Hi surveys.
$\sim3-5$. An at-scale version of this tool will greatly maximise the science output from the upcoming widefield Hi surveys.
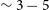
Correspondence Analysis of Incomplete Contingency Tables
-
- Journal:
- Psychometrika / Volume 53 / Issue 2 / June 1988
- Published online by Cambridge University Press:
- 01 January 2025, pp. 223-233
-
- Article
- Export citation
Statistical Analysis of Sets of Congeneric Tests
-
- Journal:
- Psychometrika / Volume 36 / Issue 2 / June 1971
- Published online by Cambridge University Press:
- 01 January 2025, pp. 109-133
-
- Article
- Export citation
Comment on “Correspondence Analysis used Complementary to Loglinear Analysis”
-
- Journal:
- Psychometrika / Volume 53 / Issue 2 / June 1988
- Published online by Cambridge University Press:
- 01 January 2025, pp. 287-291
-
- Article
- Export citation
A PROC MATRIX Program for Preference-Dissimilarity Multidimensional Scaling
-
- Journal:
- Psychometrika / Volume 51 / Issue 1 / March 1986
- Published online by Cambridge University Press:
- 01 January 2025, pp. 163-170
-
- Article
- Export citation
Correspondence Analysis used Complementary to Loglinear Analysis
-
- Journal:
- Psychometrika / Volume 50 / Issue 4 / December 1985
- Published online by Cambridge University Press:
- 01 January 2025, pp. 429-447
-
- Article
- Export citation
On the Precision of a Euclidean Structure
-
- Journal:
- Psychometrika / Volume 44 / Issue 4 / December 1979
- Published online by Cambridge University Press:
- 01 January 2025, pp. 395-408
-
- Article
- Export citation
The Principal Components of Mixed Measurement Level Multivariate Data: An Alternating Least Squares Method with Optimal Scaling Features
-
- Journal:
- Psychometrika / Volume 43 / Issue 2 / June 1978
- Published online by Cambridge University Press:
- 01 January 2025, pp. 279-281
-
- Article
- Export citation
Multidimensional Scaling of Nominal Data: The Recovery of Metric Information with Alscal
-
- Journal:
- Psychometrika / Volume 43 / Issue 3 / September 1978
- Published online by Cambridge University Press:
- 01 January 2025, pp. 367-379
-
- Article
- Export citation
Additive Structure in Qualitative Data: An Alternating Least Squares Method with Optimal Scaling Features
-
- Journal:
- Psychometrika / Volume 41 / Issue 4 / December 1976
- Published online by Cambridge University Press:
- 01 January 2025, pp. 471-503
-
- Article
- Export citation
Nonmetric Individual Differences Multidimensional Scaling: An Alternating Least Squares Method with Optimal Scaling Features
-
- Journal:
- Psychometrika / Volume 42 / Issue 1 / March 1977
- Published online by Cambridge University Press:
- 01 January 2025, pp. 7-67
-
- Article
- Export citation
Three Notes on ALSCAL
-
- Journal:
- Psychometrika / Volume 43 / Issue 3 / September 1978
- Published online by Cambridge University Press:
- 01 January 2025, pp. 433-435
-
- Article
- Export citation
Graph-based information management for retrofitting long-living assets
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 20 December 2024, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
8 - Muddied waters: The challenge of confounding
-
- Book:
- Essential Epidemiology
- Published online:
- 27 September 2024
- Print publication:
- 12 November 2024, pp 187-211
-
- Chapter
- Export citation
Chapter 7 - Extracting networks from data — the “upstream task”
- from Part II - Applications, tools, and tasks
-
- Book:
- Working with Network Data
- Published online:
- 06 June 2024
- Print publication:
- 13 June 2024, pp 83-88
-
- Chapter
-
- You have access
- Export citation

Working with Network Data
- A Data Science Perspective
-
- Published online:
- 06 June 2024
- Print publication:
- 13 June 2024
-
- Book
-
- You have access
- Export citation
