

















1. Introduction
Computing confidence intervals for neural networks (NNs) has great potential for significantly enhancing the trust of AI systems. The focus of this paper is confidence intervals provided by interval neural networks. An interval neural network consists of a pair of neural networks
 $(\underline {\phi }, \overline {\phi })$
that satisfy the componentwise inequalities
$(\underline {\phi }, \overline {\phi })$
that satisfy the componentwise inequalities
 $\underline {\phi }(y) \leq \Phi (y) \leq \overline {\phi }(y)$
for all inputs
$\underline {\phi }(y) \leq \Phi (y) \leq \overline {\phi }(y)$
for all inputs
 $y$
, where
$y$
, where
 $\Phi$
is a given neural network whose uncertainty we wish to quantify. The interval neural network is specifically trained to assess the uncertainty of
$\Phi$
is a given neural network whose uncertainty we wish to quantify. The interval neural network is specifically trained to assess the uncertainty of
 $\Phi$
, where the width of the interval
$\Phi$
, where the width of the interval
 $[\underline {\phi }(y),\overline {\phi }(y)]$
measures the confidence level of
$[\underline {\phi }(y),\overline {\phi }(y)]$
measures the confidence level of
 $\Phi (y)$
’s prediction. In recent years, such interval NNs have been used for a wide range of tasks, including uncertainty estimation [Reference Macdonald, März, Oala and Samek54, Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61, Reference Sadeghi, de Angelis and Patelli65], verifying predictions [Reference Baader, Mirman and Vechev8, Reference Mirman, Baader and Vechev56] and enhancing our understanding of their approximation properties [Reference Wang, Albarghouthi, Prakriya and Jha78]. However, recent studies have also raised issues surrounding the limitations of such intervals [Reference Baader, Mirman and Vechev8, Reference Mirman, Baader and Vechev56, Reference Wang, Albarghouthi, Prakriya and Jha78]. It has, for example, been demonstrated how interval analysis of NNs cannot necessarily verify robust predictions [Reference Mirman, Baader and Vechev56], or how for certain problems it is NP-hard to compute confidence intervals for NNs [Reference Wang, Albarghouthi, Prakriya and Jha78]. More broadly, this follows the larger trend in machine learning over the past few years of studying the limitations of AI systems [Reference Strickland70], whether it is for large language models [Reference Zhang, Press, Merrill, Liu and Smith80], predictive models [Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane40] or limitations of training algorithms [Reference Colbrook, Antun and Hansen31]. Thus, a pertinent question is the following:
$\Phi (y)$
’s prediction. In recent years, such interval NNs have been used for a wide range of tasks, including uncertainty estimation [Reference Macdonald, März, Oala and Samek54, Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61, Reference Sadeghi, de Angelis and Patelli65], verifying predictions [Reference Baader, Mirman and Vechev8, Reference Mirman, Baader and Vechev56] and enhancing our understanding of their approximation properties [Reference Wang, Albarghouthi, Prakriya and Jha78]. However, recent studies have also raised issues surrounding the limitations of such intervals [Reference Baader, Mirman and Vechev8, Reference Mirman, Baader and Vechev56, Reference Wang, Albarghouthi, Prakriya and Jha78]. It has, for example, been demonstrated how interval analysis of NNs cannot necessarily verify robust predictions [Reference Mirman, Baader and Vechev56], or how for certain problems it is NP-hard to compute confidence intervals for NNs [Reference Wang, Albarghouthi, Prakriya and Jha78]. More broadly, this follows the larger trend in machine learning over the past few years of studying the limitations of AI systems [Reference Strickland70], whether it is for large language models [Reference Zhang, Press, Merrill, Liu and Smith80], predictive models [Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane40] or limitations of training algorithms [Reference Colbrook, Antun and Hansen31]. Thus, a pertinent question is the following:
Suppose there exist feedforward interval NNs that provide uncertainty quantification of a neural network, can they be computed by an algorithm?
In this work, we continue the trend mentioned above and address the above question by investigating whether one can design classes of training datasets for which any choice of training algorithm fails to compute so-called interval NNs for uncertainty quantification. We consider the procedure proposed by Oala et al. in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61] for computing interval NNs for linear discrete inverse problems, and we show that for certain classes of training data there does not exist any algorithm that can compute approximations to these interval NNs beyond a certain accuracy.
The mechanism causing this phenomenon utilises an inherent instability of the training procedure with respect to the training datasets. This instability and the subsequent lack of reliable algorithms have several consequences (see §4.3 for a more detailed description):
The non-computability manifests in the following way: One may prove the existence of interval NNs providing uncertainty quantification for deep learning (DL) methods, over some class of input training sets. However, any algorithm trying to compute the interval NNs over this class will yield incorrect uncertainty on some input training set. In other words, the mathematical existence of minimisers does not imply algorithmic constructibility of the minimisers. The incorrectness, due to the failure of algorithmic constructibility, can manifest in two ways:
-
(1) The incorrectness can lead to the conclusion that there are no, or small, uncertainties, when in fact the uncertainties may be severe.
-
(2) Or the incorrectness can lead to the conclusion that there are severe uncertainties, when in fact, the optimal interval neural networks predict no, or small, uncertainties.
Another issue that arises from the instability is that training interval NNs will be susceptible to data poisoning. That is, the phenomenon where an attacker is allowed to alter some portion of the training data, often in an imperceptible way, causing the trained system to behave in an undesirable way for certain inputs. In this work, we demonstrate that there exist inputs such that even an arbitrarily small perturbation of the training dataset leads to significantly different interval neural networks when using standard training procedures.
1.1. Notation and outline
We start by introducing some useful notation. The main essence of this paper is the study of neural networks, and we therefore start by giving a precise definition of this concept. Let
 $K$
be a natural number and let
$K$
be a natural number and let
 $\mathbf{N} \,:\!=\, (N_0, N_{1}, \ldots ,N_{K-1}, N_K) \in \mathbb{N}^{K+1}$
. A neural network with dimension
$\mathbf{N} \,:\!=\, (N_0, N_{1}, \ldots ,N_{K-1}, N_K) \in \mathbb{N}^{K+1}$
. A neural network with dimension
 $(\mathbf{N},K)$
is a map
$(\mathbf{N},K)$
is a map
 $\Phi \,:\, {\mathbb{R}}^{N_0} \to {\mathbb{R}}^{N_K}$
such that
$\Phi \,:\, {\mathbb{R}}^{N_0} \to {\mathbb{R}}^{N_K}$
such that
 \begin{align*} \Phi (x) \,:\!=\, V^{(K)} \circ \sigma \circ V^{(K-1)} \circ \sigma \circ V^{(K-2)} \circ \cdots \circ \sigma \circ V^{(1)}x, \end{align*}
\begin{align*} \Phi (x) \,:\!=\, V^{(K)} \circ \sigma \circ V^{(K-1)} \circ \sigma \circ V^{(K-2)} \circ \cdots \circ \sigma \circ V^{(1)}x, \end{align*}
where, for
 $k = 1, \ldots , K$
, the map
$k = 1, \ldots , K$
, the map
 $V^{(k)}$
is an affine map from
$V^{(k)}$
is an affine map from
 ${\mathbb{R}}^{N_{k-1}} \to {\mathbb{R}}^{N_k}$
, that is
${\mathbb{R}}^{N_{k-1}} \to {\mathbb{R}}^{N_k}$
, that is
 $V^{(k)} x^{(k)} = W^{(k)}x^{(k)} + b^{(k)}$
, where
$V^{(k)} x^{(k)} = W^{(k)}x^{(k)} + b^{(k)}$
, where
 $b^{(k)} \in {\mathbb{R}}^{N_k}$
and
$b^{(k)} \in {\mathbb{R}}^{N_k}$
and
 $W^{(k)} \in {\mathbb{R}}^{N_{k-1} \times N_k}$
. The map
$W^{(k)} \in {\mathbb{R}}^{N_{k-1} \times N_k}$
. The map
 $\sigma \,:\, {\mathbb{R}} \to {\mathbb{R}}$
is interpreted as a coordinatewise map and is called the non-linearity or activation function: typically
$\sigma \,:\, {\mathbb{R}} \to {\mathbb{R}}$
is interpreted as a coordinatewise map and is called the non-linearity or activation function: typically
 $\sigma$
is chosen to be continuous and non-polynomial, in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61]
$\sigma$
is chosen to be continuous and non-polynomial, in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61]
 $\sigma$
is chosen to be the ReLU function.
$\sigma$
is chosen to be the ReLU function.
Two other useful concepts for this paper are the elementwise min and max functions, as these play an essential role in the construction of interval neural networks and in our proofs. For any vectors
 $x^1,x^2 \in {\mathbb{R}}^n$
, we define
$x^1,x^2 \in {\mathbb{R}}^n$
, we define
 $\max \{x^1,x^2\} = z^{max}$
and
$\max \{x^1,x^2\} = z^{max}$
and
 $\min \{x^1,x^2\} = z^{min}$
, with
$\min \{x^1,x^2\} = z^{min}$
, with
 \begin{align*} z^{max}_i = \max \{x^1_i, x^2_i\} = \begin{cases} x^1_{i}, &\; \text{if} \: x^1_i \geq x^2_i\\ x^2_i, &\; \text{otherwise} \end{cases} \quad \text{and} \quad z^{min}_i = \min \{x^1_i, x^2_i\} = \begin{cases} x^1_{i}, &\; \text{if} \: x^1_i \leq x^2_i\\ x^2_i, &\; \text{otherwise.} \end{cases} \end{align*}
\begin{align*} z^{max}_i = \max \{x^1_i, x^2_i\} = \begin{cases} x^1_{i}, &\; \text{if} \: x^1_i \geq x^2_i\\ x^2_i, &\; \text{otherwise} \end{cases} \quad \text{and} \quad z^{min}_i = \min \{x^1_i, x^2_i\} = \begin{cases} x^1_{i}, &\; \text{if} \: x^1_i \leq x^2_i\\ x^2_i, &\; \text{otherwise.} \end{cases} \end{align*}
for
 $i = 1, \ldots , n$
.
$i = 1, \ldots , n$
.
Finally, to increase readability, we include a brief outline of the contents. The paper is structured as follows:
-
• In section 2, we present the key mathematical objects, namely inverse problems and interval neural networks, and we present our mathematical assumptions about these objects.
-
• In section 3, we include a table of notation to ease readability.
-
• In section 4, we present the main theorem and some of its consequences.
-
• In section 5, we connect our findings to the existing literature.
-
• In section 6, we present the mathematical preliminaries needed for the proof of the main theorem, more specifically, we introduce the computability framework of the Solvability Complexity Index (SCI) hierarchy and some key results from [Reference Bastounis, Hansen and Vlačić11]. We end the section by formulating the main theorem in the language of the SCI hierarchy.
-
• Finally, we present all the proofs of this paper in section 7, and this includes the proofs of some preliminary lemmas and finally, the proof of the main theorem itself.
2. Inverse problems and interval neural networks
2.1. Linear discrete inverse problems
Throughout this paper, we study the construction of interval neural networks in the context of solving linear discrete inverse problems. A linear discrete inverse problem can be expressed as follows:
 \begin{equation} \text{Given measurements $y = Ax +e \in {\mathbb{R}}^m$ of $x \in {\mathbb{R}}^N$, recover $x$.} \end{equation}
\begin{equation} \text{Given measurements $y = Ax +e \in {\mathbb{R}}^m$ of $x \in {\mathbb{R}}^N$, recover $x$.} \end{equation}
Here,
 $A$
is an
$A$
is an
 $m\times N$
real-valued matrix modelling the measurement process of
$m\times N$
real-valued matrix modelling the measurement process of
 $x$
, and
$x$
, and
 $e$
models measurement noise. While seemingly simple, this equation is sufficiently expressive to model many real-world applications. Examples include most types of medical and industrial imaging (Magnetic Resonance Imaging (MRI), Computerised Tomography (CT), and microscopy) [Reference Adcock and Hansen3], image deblurring, statistical estimation [Reference Vogel75], etc. These types of problems have been extensively studied in sparse recovery and compressed sensing when
$e$
models measurement noise. While seemingly simple, this equation is sufficiently expressive to model many real-world applications. Examples include most types of medical and industrial imaging (Magnetic Resonance Imaging (MRI), Computerised Tomography (CT), and microscopy) [Reference Adcock and Hansen3], image deblurring, statistical estimation [Reference Vogel75], etc. These types of problems have been extensively studied in sparse recovery and compressed sensing when
 $x$
is a sparse vector or a vector with some structured sparsity [Reference Adcock and Hansen2, Reference Adcock and Hansen3, Reference Adcock, Hansen, Poon and Roman4, Reference Bastounis and Hansen9, Reference Boyer, Bigot and Weiss22, Reference Candès, Romberg and Tao24, Reference Fannjiang and Strohmer37, Reference Juditsky, Kilinç-Karzan and Nemirovski49]. However, recent developments have led to a plethora of AI techniques [Reference Antun, Renna, Poon, Adcock and Hansen5, Reference Arridge, Maass, Öktem and Schönlieb7, Reference Gottschling, Antun, Hansen and Adcock42, Reference Hammernik, Klatzer, Kobler, Recht, Sodickson, Pock and Knoll44, Reference Jin, McCann, Froustey and Unser48, Reference McCann, Jin and Unser55, Reference Ongie, Jalal, Metzler, Baraniuk, Dimakis and Willett62] for solving these types of problems.
$x$
is a sparse vector or a vector with some structured sparsity [Reference Adcock and Hansen2, Reference Adcock and Hansen3, Reference Adcock, Hansen, Poon and Roman4, Reference Bastounis and Hansen9, Reference Boyer, Bigot and Weiss22, Reference Candès, Romberg and Tao24, Reference Fannjiang and Strohmer37, Reference Juditsky, Kilinç-Karzan and Nemirovski49]. However, recent developments have led to a plethora of AI techniques [Reference Antun, Renna, Poon, Adcock and Hansen5, Reference Arridge, Maass, Öktem and Schönlieb7, Reference Gottschling, Antun, Hansen and Adcock42, Reference Hammernik, Klatzer, Kobler, Recht, Sodickson, Pock and Knoll44, Reference Jin, McCann, Froustey and Unser48, Reference McCann, Jin and Unser55, Reference Ongie, Jalal, Metzler, Baraniuk, Dimakis and Willett62] for solving these types of problems.
In many of the applications listed above the
 $\mathrm{rank}(A) \lt N$
, either because
$\mathrm{rank}(A) \lt N$
, either because
 $m \lt N$
or because the matrix
$m \lt N$
or because the matrix
 $A$
is rank-deficient. In both cases, the kernel of the matrix is non-trivial, which means that even in the noiseless setting, the linear system in (2.1) does not have a unique solution. Another fundamental challenge in inverse problems is ill-conditioning, which can significantly impact the solutions stability and reliability. At its core, an ill-conditioned inverse problem is one where small changes in the measured data can lead to disproportionately large changes in the reconstructed solution; in other words, the problem is sensitive to inexact representations of the input data. To make the problem tractable whenever
$A$
is rank-deficient. In both cases, the kernel of the matrix is non-trivial, which means that even in the noiseless setting, the linear system in (2.1) does not have a unique solution. Another fundamental challenge in inverse problems is ill-conditioning, which can significantly impact the solutions stability and reliability. At its core, an ill-conditioned inverse problem is one where small changes in the measured data can lead to disproportionately large changes in the reconstructed solution; in other words, the problem is sensitive to inexact representations of the input data. To make the problem tractable whenever
 $\mathrm{rank}(A) \lt N$
or when
$\mathrm{rank}(A) \lt N$
or when
 $A$
is ill-conditioned, it is therefore customary to introduce a set
$A$
is ill-conditioned, it is therefore customary to introduce a set
 $\mathcal{U}_1\subset {\mathbb{R}}^N$
called the model class [Reference Adcock and Hansen3, Reference Candès, Romberg and Tao24, Reference Juditsky, Kilinç-Karzan and Nemirovski49] and assume that
$\mathcal{U}_1\subset {\mathbb{R}}^N$
called the model class [Reference Adcock and Hansen3, Reference Candès, Romberg and Tao24, Reference Juditsky, Kilinç-Karzan and Nemirovski49] and assume that
 $x$
belongs to this set. We may, therefore, rewrite the noiseless problem as follows:
$x$
belongs to this set. We may, therefore, rewrite the noiseless problem as follows:
 \begin{equation} \text{Given measurements } y = Ax \in {\mathbb{R}}^m \text{ of } x \in \mathcal{U}_1\subset {\mathbb{R}}^N, \text{ recover } x. \end{equation}
\begin{equation} \text{Given measurements } y = Ax \in {\mathbb{R}}^m \text{ of } x \in \mathcal{U}_1\subset {\mathbb{R}}^N, \text{ recover } x. \end{equation}
For the remainder of this paper, we consider the noiseless version of Eq. (2.1) presented above, because providing results about computational barriers in the noiseless setting gives stronger results. If constructing optimal interval neural networks is non-computable in the noiseless setting, there should be no hope of constructing optimal interval neural networks from noisy measurements either.
Traditional methods for solving (2.2) typically make explicit assumptions about the set
 $\mathcal{U}_1$
and design the reconstruction mapping based on this choice. Examples of sets
$\mathcal{U}_1$
and design the reconstruction mapping based on this choice. Examples of sets
 $\mathcal{U}_1$
found in the literature are sparse vectors, union of subspaces, manifolds, etc. [Reference Bengio, Courville and Vincent18, Reference Candès, Romberg and Tao24, Reference Ma and Fu53]. Nowadays, learning-based methods are popular alternatives to the traditional methods whenever one has access to a dataset,
$\mathcal{U}_1$
found in the literature are sparse vectors, union of subspaces, manifolds, etc. [Reference Bengio, Courville and Vincent18, Reference Candès, Romberg and Tao24, Reference Ma and Fu53]. Nowadays, learning-based methods are popular alternatives to the traditional methods whenever one has access to a dataset,
 \begin{equation} \mathcal{T} = \{(x^{(1)}, y^{(1)}), \ldots , (x^{(\ell )}, y^{(\ell )})\}\subset {\mathbb{R}}^{N}\times {\mathbb{R}}^m, \end{equation}
\begin{equation} \mathcal{T} = \{(x^{(1)}, y^{(1)}), \ldots , (x^{(\ell )}, y^{(\ell )})\}\subset {\mathbb{R}}^{N}\times {\mathbb{R}}^m, \end{equation}
of training examples. For these methods, one seeks to find an NN
 $\Phi \colon {\mathbb{R}}^m\to {\mathbb{R}}^N$
for which
$\Phi \colon {\mathbb{R}}^m\to {\mathbb{R}}^N$
for which
 $\Phi (y)\approx x$
, for each
$\Phi (y)\approx x$
, for each
 $(x,y) \in \mathcal{T}$
and preferably also for all
$(x,y) \in \mathcal{T}$
and preferably also for all
 $(x,y)$
in some holdout test set. Thus, for learning-based methods, one does not describe
$(x,y)$
in some holdout test set. Thus, for learning-based methods, one does not describe
 $\mathcal{U}_1$
mathematically as for the traditional methods, but one implicitly aims to learn
$\mathcal{U}_1$
mathematically as for the traditional methods, but one implicitly aims to learn
 $\mathcal{U}_1$
from the data
$\mathcal{U}_1$
from the data
 $\mathcal{T}$
, by training a neural network which maps
$\mathcal{T}$
, by training a neural network which maps
 $Ax \mapsto x$
for each
$Ax \mapsto x$
for each
 $x \in \mathcal{U}_1$
.
$x \in \mathcal{U}_1$
.
2.2. Computing interval neural networks for inverse problems
In [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61], the authors proposed to compute a pair of interval NNs
 $\overline {\phi },\underline {\phi } \colon {\mathbb{R}}^m\to {\mathbb{R}}^N$
for the problem in (2.1), whose objective is to provide confidence intervals for an NN
$\overline {\phi },\underline {\phi } \colon {\mathbb{R}}^m\to {\mathbb{R}}^N$
for the problem in (2.1), whose objective is to provide confidence intervals for an NN
 $\Phi \colon {\mathbb{R}}^m\to {\mathbb{R}}^N$
trained to solve the inverse problem. The confidence intervals would be computed componentwise as
$\Phi \colon {\mathbb{R}}^m\to {\mathbb{R}}^N$
trained to solve the inverse problem. The confidence intervals would be computed componentwise as
 $\overline {\phi }(y') - \underline {\phi }(y')$
for inputs
$\overline {\phi }(y') - \underline {\phi }(y')$
for inputs
 $y'$
, by ensuring that the trained interval NNs satisfy
$y'$
, by ensuring that the trained interval NNs satisfy
 \begin{equation*} \underline {\phi }(y)\leq \Phi (y) \leq \overline {\phi }(y) \, \text{ componentwise for all inputs } \, y. \end{equation*}
\begin{equation*} \underline {\phi }(y)\leq \Phi (y) \leq \overline {\phi }(y) \, \text{ componentwise for all inputs } \, y. \end{equation*}
The idea proposed in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61] is then to utilise the componentwise confidence intervals provided by these NNs to detect potential failure modes for
 $\Phi$
. The method proposed in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61] works as follows. Given a dataset
$\Phi$
. The method proposed in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61] works as follows. Given a dataset
 $\mathcal{T}$
as in (2.3), one first trains a feedforward ReLU NN
$\mathcal{T}$
as in (2.3), one first trains a feedforward ReLU NN
 $\Phi \colon {\mathbb{R}}^{m}\to {\mathbb{R}}^N$
using a squared error loss function. Then, given the weights
$\Phi \colon {\mathbb{R}}^{m}\to {\mathbb{R}}^N$
using a squared error loss function. Then, given the weights
 $W^{(k)}$
and the biases
$W^{(k)}$
and the biases
 $b^{(k)}$
of
$b^{(k)}$
of
 $\Phi$
, one trains two interval NNs
$\Phi$
, one trains two interval NNs
 $\underline {\phi },\overline {\phi } \colon {\mathbb{R}}^m\to {\mathbb{R}}^N$
with the same number of layers as
$\underline {\phi },\overline {\phi } \colon {\mathbb{R}}^m\to {\mathbb{R}}^N$
with the same number of layers as
 $\Phi$
, by minimising the objective function
$\Phi$
, by minimising the objective function
 \begin{equation} F_{{\mathcal{T}}, \beta }(\underline {\phi },\overline {\phi }) \,:\!=\, \sum _{(x,y) \in {\mathcal{T}}} \| \max \{x - \overline {\phi }(y), 0 \} \|_2^2 + \| \max \{ \underline {\phi }(y) - x, 0 \} \|_2^2 + \beta \| \overline {\phi }(y) - \underline {\phi }(y) \|_1, \quad \beta \gt 0 \end{equation}
\begin{equation} F_{{\mathcal{T}}, \beta }(\underline {\phi },\overline {\phi }) \,:\!=\, \sum _{(x,y) \in {\mathcal{T}}} \| \max \{x - \overline {\phi }(y), 0 \} \|_2^2 + \| \max \{ \underline {\phi }(y) - x, 0 \} \|_2^2 + \beta \| \overline {\phi }(y) - \underline {\phi }(y) \|_1, \quad \beta \gt 0 \end{equation}
subject to the constraints
 $\underline {W}^{(k)}\leq W^{(k)} \leq \overline {W}^{(k)}$
and
$\underline {W}^{(k)}\leq W^{(k)} \leq \overline {W}^{(k)}$
and
 $\underline {b}^{(k)}\leq b^{(k)} \leq \overline {b}^{(k)}$
, where all inequalities are meant entrywise, and
$\underline {b}^{(k)}\leq b^{(k)} \leq \overline {b}^{(k)}$
, where all inequalities are meant entrywise, and
 $\underline {W}^{(k)}, \overline {W}^{(k)}, \underline {b}^{(k)}, \overline {b}^{(k)}$
are the weights and the biases of
$\underline {W}^{(k)}, \overline {W}^{(k)}, \underline {b}^{(k)}, \overline {b}^{(k)}$
are the weights and the biases of
 $\underline {\phi },\overline {\phi }$
, respectively. The goal of minimising Eq. (2.4) is to provide the sharpest possible bounds for the set
$\underline {\phi },\overline {\phi }$
, respectively. The goal of minimising Eq. (2.4) is to provide the sharpest possible bounds for the set
 $X_y \,:\!=\, \{x \in \pi _1({\mathcal{T}}) \: : \: y = Ax \}$
for each
$X_y \,:\!=\, \{x \in \pi _1({\mathcal{T}}) \: : \: y = Ax \}$
for each
 $y \in \pi _2({\mathcal{T}})$
, in the sense that the interval
$y \in \pi _2({\mathcal{T}})$
, in the sense that the interval
 $[\underline {\phi }(y),\overline {\phi }(y)]$
should be the smallest possible with the property that
$[\underline {\phi }(y),\overline {\phi }(y)]$
should be the smallest possible with the property that
 $\underline {\phi }(y) \leq x \leq \overline {\phi }(y)$
for all
$\underline {\phi }(y) \leq x \leq \overline {\phi }(y)$
for all
 $x \in X_y$
, where the inequalities are meant componentwise, and where
$x \in X_y$
, where the inequalities are meant componentwise, and where
 $\pi _1({\mathcal{T}})$
and
$\pi _1({\mathcal{T}})$
and
 $\pi _2({\mathcal{T}})$
are the projections onto the coordinates of the training set
$\pi _2({\mathcal{T}})$
are the projections onto the coordinates of the training set
 $\mathcal{T}$
denoted by
$\mathcal{T}$
denoted by
 \begin{align} \pi _1({\mathcal{T}}) \,:\!=\, \{x \in {\mathbb{R}}^N \: : \: (x,y) \in {\mathcal{T}} \} \quad \text{and} \quad \pi _2({\mathcal{T}}) \,:\!=\, \{y \in {\mathbb{R}}^m \: : \: (x,y) \in {\mathcal{T}} \}. \end{align}
\begin{align} \pi _1({\mathcal{T}}) \,:\!=\, \{x \in {\mathbb{R}}^N \: : \: (x,y) \in {\mathcal{T}} \} \quad \text{and} \quad \pi _2({\mathcal{T}}) \,:\!=\, \{y \in {\mathbb{R}}^m \: : \: (x,y) \in {\mathcal{T}} \}. \end{align}
The observation made in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61] is that one can design a clever architecture for
 $\underline {\phi },\overline {\phi }$
that can mimic interval arithmetic for the weights and biases by using the interval property of these parameters. This architecture heavily exploits the fact that the ReLU activation function ensures that the input to each layer is non-negative. We refer to [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61], for further details on this, but we note that this ensures that
$\underline {\phi },\overline {\phi }$
that can mimic interval arithmetic for the weights and biases by using the interval property of these parameters. This architecture heavily exploits the fact that the ReLU activation function ensures that the input to each layer is non-negative. We refer to [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61], for further details on this, but we note that this ensures that
 $\underline {\phi }(y)\leq \Phi (y) \leq \overline {\phi }(y)$
for all
$\underline {\phi }(y)\leq \Phi (y) \leq \overline {\phi }(y)$
for all
 $y \in {\mathbb{R}}^m$
.
$y \in {\mathbb{R}}^m$
.
Our goal in this work is to investigate whether there exist classes of training sets, for which no algorithm can reliably compute interval NNs. Following [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61], these interval NNs must necessarily depend on the pre-trained NN
 $\Phi$
, the optimisation parameter
$\Phi$
, the optimisation parameter
 $\beta \in {\mathbb{R}}$
, and the considered training set
$\beta \in {\mathbb{R}}$
, and the considered training set
 $\mathcal{T}$
. In this work, we assume throughout that
$\mathcal{T}$
. In this work, we assume throughout that
 $\beta \gt 0$
is a given fixed dyadic number (a number which is exactly representable on a computer). In addition, we make several well-posedness assumptions about
$\beta \gt 0$
is a given fixed dyadic number (a number which is exactly representable on a computer). In addition, we make several well-posedness assumptions about
 $\mathcal{T}$
and
$\mathcal{T}$
and
 $\Phi$
to ensure that our results are not a consequence of unreasonable training data or poor training of the neural network
$\Phi$
to ensure that our results are not a consequence of unreasonable training data or poor training of the neural network
 $\Phi$
.
$\Phi$
.
We start with assumptions about
 $\mathcal{T}$
. Let
$\mathcal{T}$
. Let
 $B_1^N(0)$
denote the open unit Euclidean ball in
$B_1^N(0)$
denote the open unit Euclidean ball in
 ${\mathbb{R}}^N$
, and assume that for a given integer
${\mathbb{R}}^N$
, and assume that for a given integer
 $\ell \gt 1$
and a given model class
$\ell \gt 1$
and a given model class
 $\mathcal{U}_1 \subseteq B_1^N(0)$
, each
$\mathcal{U}_1 \subseteq B_1^N(0)$
, each
 $x$
-coordinate of the training set
$x$
-coordinate of the training set
 $\mathcal{T}=\{(x^{(i)}, Ax^{(i)})\}_{i=1}^{\ell }$
belongs to the model class
$\mathcal{T}=\{(x^{(i)}, Ax^{(i)})\}_{i=1}^{\ell }$
belongs to the model class
 $\mathcal{U}_1$
. That is, the set
$\mathcal{U}_1$
. That is, the set
 $\mathcal{T}$
is a member of
$\mathcal{T}$
is a member of
 \begin{equation} T_{\ell ,\mathcal{U}_1} \,:\!=\, \{ \{(x^{(1)},Ax^{(1)}),\ldots , (x^{(\ell )}, Ax^{(\ell )})\}\subset \mathcal{U}_1\times A(\mathcal{U}_1) \,:\, x^{(1)}, \ldots , x^{(\ell )} \in \mathcal{U}_1 \}. \end{equation}
\begin{equation} T_{\ell ,\mathcal{U}_1} \,:\!=\, \{ \{(x^{(1)},Ax^{(1)}),\ldots , (x^{(\ell )}, Ax^{(\ell )})\}\subset \mathcal{U}_1\times A(\mathcal{U}_1) \,:\, x^{(1)}, \ldots , x^{(\ell )} \in \mathcal{U}_1 \}. \end{equation}
We require that
 $\mathcal{U}_1\subset B_{1}^{N}(0)$
because we are interested in measuring the error of an algorithm relative to the size of the training sets, and
$\mathcal{U}_1\subset B_{1}^{N}(0)$
because we are interested in measuring the error of an algorithm relative to the size of the training sets, and
 $B_{1}^{N}(0)$
is an arbitrary, yet practical, restriction on the size of the training sets.
$B_{1}^{N}(0)$
is an arbitrary, yet practical, restriction on the size of the training sets.
Throughout the paper, to mitigate the effects due to poor training of
 $\Phi$
, we assume that for a given training set
$\Phi$
, we assume that for a given training set
 $\mathcal{T}$
, the corresponding pre-trained neural network
$\mathcal{T}$
, the corresponding pre-trained neural network
 $\Phi$
satisfies
$\Phi$
satisfies
 $\Phi (y) \in {\mathcal{V}}_{{\mathcal{T}}}(y)$
for all
$\Phi (y) \in {\mathcal{V}}_{{\mathcal{T}}}(y)$
for all
 $y \in {\mathbb{R}}^m$
, where
$y \in {\mathbb{R}}^m$
, where
 ${\mathcal{V}}_{{\mathcal{T}}} \,:\, {\mathbb{R}}^m \rightrightarrows {\mathbb{R}}^n$
is the potentially multi-valued map given by
${\mathcal{V}}_{{\mathcal{T}}} \,:\, {\mathbb{R}}^m \rightrightarrows {\mathbb{R}}^n$
is the potentially multi-valued map given by
 \begin{equation} {\mathcal{V}}_{{\mathcal{T}}}(y)\,:\!=\, \mathop {argmin} \limits_{z \in {\mathbb{R}}^N} \mathrm{dist}(z, \pi _1({\mathcal{T}})) + \|Az-y\|_{2}, \end{equation}
\begin{equation} {\mathcal{V}}_{{\mathcal{T}}}(y)\,:\!=\, \mathop {argmin} \limits_{z \in {\mathbb{R}}^N} \mathrm{dist}(z, \pi _1({\mathcal{T}})) + \|Az-y\|_{2}, \end{equation}
with
 $\mathrm{dist}(z,\pi _1(\mathcal{T})) \,:\!=\, \inf _{u\in \pi _1({\mathcal{T}})}\|z-u\|_{2}$
, and where
$\mathrm{dist}(z,\pi _1(\mathcal{T})) \,:\!=\, \inf _{u\in \pi _1({\mathcal{T}})}\|z-u\|_{2}$
, and where
 $\pi _1({\mathcal{T}})$
is as given in Eq. (2.5). The double arrow notation
$\pi _1({\mathcal{T}})$
is as given in Eq. (2.5). The double arrow notation
 $\rightrightarrows$
indicates a multi-valued map. This mapping is inspired by the notion of instance optimality, introduced in [Reference Cohen, Dahmen and DeVore29], and later developed in works such as [Reference Bourrier, Davies, Peleg, Pérez and Gribonval21, Reference DeVore, Petrova and Wojtaszczyk35, Reference Gottschling, Campodonico, Antun and Hansen43]. Since
$\rightrightarrows$
indicates a multi-valued map. This mapping is inspired by the notion of instance optimality, introduced in [Reference Cohen, Dahmen and DeVore29], and later developed in works such as [Reference Bourrier, Davies, Peleg, Pérez and Gribonval21, Reference DeVore, Petrova and Wojtaszczyk35, Reference Gottschling, Campodonico, Antun and Hansen43]. Since
 $x \in \pi _1({\mathcal{T}})$
implies that
$x \in \pi _1({\mathcal{T}})$
implies that
 $x \in {\mathcal{V}}_{{\mathcal{T}}}(Ax)$
, we get that the neural network
$x \in {\mathcal{V}}_{{\mathcal{T}}}(Ax)$
, we get that the neural network
 $\Phi$
has an excellent performance on all elements in
$\Phi$
has an excellent performance on all elements in
 $\pi _2({\mathcal{T}})$
, where
$\pi _2({\mathcal{T}})$
, where
 $\pi _2({\mathcal{T}})$
is as given in Eq. (2.5), which means that
$\pi _2({\mathcal{T}})$
is as given in Eq. (2.5), which means that
 $\Phi$
maps
$\Phi$
maps
 $y = Ax$
to a unique
$y = Ax$
to a unique
 $x$
or selects one out of the (many) solutions when
$x$
or selects one out of the (many) solutions when
 $\pi _1({\mathcal{T}})$
has redundant elements.
$\pi _1({\mathcal{T}})$
has redundant elements.
Further, we need to make sure that the classes of neural networks that we are working with are rich enough to guarantee the existence of well-behaved interval neural networks. We do not wish for our computational barriers to arise due to the lack of existence of interval neural networks nor the lack of expressiveness of these networks. The following assumption is a technical assumption that ensures this.
Assumption 2.1. For a given fixed integer
 $\ell \geq 1$
, we assume that
$\ell \geq 1$
, we assume that
 $\mathcal{NN}_{\ell }$
is a class of neural networks such that for any collection
$\mathcal{NN}_{\ell }$
is a class of neural networks such that for any collection
 $\mathcal{T} = \left \{(x^{(1)}, y^{(1)}), \ldots , (x^{(\ell )}, y^{(\ell )})\right \}\subset {\mathbb{R}}^{N} \times {\mathbb{R}}^m$
, where each
$\mathcal{T} = \left \{(x^{(1)}, y^{(1)}), \ldots , (x^{(\ell )}, y^{(\ell )})\right \}\subset {\mathbb{R}}^{N} \times {\mathbb{R}}^m$
, where each
 $y$
-coordinate is distinct, the following holds:
$y$
-coordinate is distinct, the following holds:
-
(i) (
 $\ell$
-interpolatory): There exists a neural network
$\Psi \in \mathcal{NN}_{\ell }$
, such that
$\Psi (y) = x$
for each
$(x,y)\in \mathcal{T}$
.
$\ell$
-interpolatory): There exists a neural network
$\Psi \in \mathcal{NN}_{\ell }$
, such that
$\Psi (y) = x$
for each
$(x,y)\in \mathcal{T}$
. -
(ii) For any choice of
$x' \in {\mathbb{R}}^{N}$
, any
$k \in \{1,\ldots ,\ell \}$
and any
$\Psi \in \mathcal{NN}_{\ell }$
satisfying (i), there exist neural networks
$\underline {\phi },\overline {\phi } \in \mathcal{NN}_{\ell }$
, such that








-
(a)
$\underline {\phi }(y) \leq \Psi (y) \leq \overline {\phi }(y)$
for all
$y \in {\mathbb{R}}^m$
, and -
(b) such that
$\underline {\phi }(y) = \overline {\phi }(y) = x$
for all
$(x,y)\in \mathcal{T}\setminus \{ (x^{(k)},y^{(k)})\}$
, and -
(c)
$\underline {\phi }(y^{(k)}) = \min \{x',x^{(k)}\}$
and
$\overline {\phi }(y^{(k)}) = \max \{x',x^{(k)}\}$
.






Here, the first condition states that there exist well-trained neural networks
 $\Psi$
in our function class, that is, a neural network that interpolates all the training data in the set
$\Psi$
in our function class, that is, a neural network that interpolates all the training data in the set
 $\mathcal{T}$
for any collection
$\mathcal{T}$
for any collection
 $\mathcal{T}$
of distinct points. The second condition is centred on the existence of certain interval neural networks in our function class. Conditions (a)-(c) state that for any arbitrarily chosen input pair
$\mathcal{T}$
of distinct points. The second condition is centred on the existence of certain interval neural networks in our function class. Conditions (a)-(c) state that for any arbitrarily chosen input pair
 $(x^{(k)},y^{(k)}) \in {\mathcal{T}}$
and an arbitrarily chosen
$(x^{(k)},y^{(k)}) \in {\mathcal{T}}$
and an arbitrarily chosen
 $x' \in {\mathbb{R}}^N$
, there exist neural networks
$x' \in {\mathbb{R}}^N$
, there exist neural networks
 $\underline {\phi }$
and
$\underline {\phi }$
and
 $\overline {\phi }$
in our function class such that
$\overline {\phi }$
in our function class such that
-
•
$\overline {\phi }$
interpolates the points
$[\mathcal{T}\setminus \{ (x^{(k)},y^{(k)})\}] \cup \{(\!\max \{x',x^{(k)}\}, y^{(k)})\}$
, -
•
$\underline {\phi }$
interpolates the points
$[\mathcal{T}\setminus \{ (x^{(k)},y^{(k)})\}] \cup \{(\!\min \{x',x^{(k)}\}, y^{(k)})\}$
, -
• and such that
$\underline {\phi }$
and
$\overline {\phi }$
provide elementwise upper and lower bounds for the chosen network
$\Psi$
.







Our main motivation for introducing Assumption 2.1 is to allow the most general results possible, while securing existence of well-behaved interval neural networks. We do not restrict our attention to classes of ReLU networks, but rather extend our results to any class of neural networks that satisfies Assumption 2.1. We wish to highlight that Assumption 2.1 is satisfied by any class of ReLU networks of fixed depth greater than or equal to 2. We illustrate this in section A. Thus, proving results for classes of NNs that satisfy Assumption 2.1 is strictly stronger than addressing the classes of neural networks that are considered by the authors in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61].
We assume throughout the paper that all the neural networks that we are working with are contained in a class
 ${\mathcal{N} \mathcal{N}}_{\ell }$
that satisfies Assumption 2.1. In particular we assume that, for a given training set
${\mathcal{N} \mathcal{N}}_{\ell }$
that satisfies Assumption 2.1. In particular we assume that, for a given training set
 $\mathcal{T}$
and a given class of neural networks
$\mathcal{T}$
and a given class of neural networks
 ${\mathcal{N} \mathcal{N}}_{\ell }$
, that satisfies Assumption 2.1, the pre-trained neural network
${\mathcal{N} \mathcal{N}}_{\ell }$
, that satisfies Assumption 2.1, the pre-trained neural network
 $\Phi$
belongs to the set:
$\Phi$
belongs to the set:
 \begin{equation} \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell }) \,:\!=\, \{\Psi \in {\mathcal{N} \mathcal{N}}_{\ell } \,:\, \Psi (y) \in {\mathcal{V}}_{{\mathcal{T}}}(y) \text{ for all } y \in {\mathbb{R}}^m \}. \end{equation}
\begin{equation} \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell }) \,:\!=\, \{\Psi \in {\mathcal{N} \mathcal{N}}_{\ell } \,:\, \Psi (y) \in {\mathcal{V}}_{{\mathcal{T}}}(y) \text{ for all } y \in {\mathbb{R}}^m \}. \end{equation}
We also require that the interval neural networks
 $\underline {\phi }$
and
$\underline {\phi }$
and
 $\overline {\phi }$
belong to
$\overline {\phi }$
belong to
 ${\mathcal{N} \mathcal{N}}_{\ell }$
, and that they respect the interval property
${\mathcal{N} \mathcal{N}}_{\ell }$
, and that they respect the interval property
 $\underline {\phi }(y) \leq \Phi (y) \leq \overline {\phi }(y)$
for all
$\underline {\phi }(y) \leq \Phi (y) \leq \overline {\phi }(y)$
for all
 $y \in {\mathbb{R}}^m$
. In order to ensure this, we introduce the following optimisation classes:
$y \in {\mathbb{R}}^m$
. In order to ensure this, we introduce the following optimisation classes:
 $$\begin{align}{\mathcal{N} \mathcal{N}}_{\Phi }^u &= \{\underline {\phi }\,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N \: | \: \underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\ell } \; \text{and} \; \underline {\phi }(y) \leq \Phi (y) \: \text{for all} \: y \in {\mathbb{R}}^m\}, \; \text{and}\end{align}$$
$$\begin{align}{\mathcal{N} \mathcal{N}}_{\Phi }^u &= \{\underline {\phi }\,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N \: | \: \underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\ell } \; \text{and} \; \underline {\phi }(y) \leq \Phi (y) \: \text{for all} \: y \in {\mathbb{R}}^m\}, \; \text{and}\end{align}$$
 $$\begin{align}{\mathcal{N} \mathcal{N}}_{\Phi }^o &= \{\overline {\phi }\,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N \: | \: \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\ell } \; \text{and} \; \Phi (y) \leq \overline {\phi }(y) \: \text{for all} \: y \in {\mathbb{R}}^m\}\end{align}$$
$$\begin{align}{\mathcal{N} \mathcal{N}}_{\Phi }^o &= \{\overline {\phi }\,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N \: | \: \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\ell } \; \text{and} \; \Phi (y) \leq \overline {\phi }(y) \: \text{for all} \: y \in {\mathbb{R}}^m\}\end{align}$$
Remark 2.2. The optimisation classes above state properties of the neural networks
 $\Phi ,\underline {\phi }$
and
$\Phi ,\underline {\phi }$
and
 $\overline {\phi }$
, rather than properties of the parameters of these networks. This gives us much greater flexibility in designing these NNs, because the condition
$\overline {\phi }$
, rather than properties of the parameters of these networks. This gives us much greater flexibility in designing these NNs, because the condition
 $\underline {\phi }(y)\leq \Phi (y) \leq \overline {\phi }(y)$
is strictly weaker than the conditions of having both
$\underline {\phi }(y)\leq \Phi (y) \leq \overline {\phi }(y)$
is strictly weaker than the conditions of having both
 $\underline {W}^{(k)}\leq W^{(k)} \leq \overline {W}^{(k)}$
and
$\underline {W}^{(k)}\leq W^{(k)} \leq \overline {W}^{(k)}$
and
 $\underline {b}^{(k)}\leq b^{(k)} \leq \overline {b}^{(k)}$
.
$\underline {b}^{(k)}\leq b^{(k)} \leq \overline {b}^{(k)}$
.
Remark 2.3. In [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61], the neural networks
 $\Phi$
and
$\Phi$
and
 $\underline {\phi },\overline {\phi }$
have slightly different architectures, due to the fact that
$\underline {\phi },\overline {\phi }$
have slightly different architectures, due to the fact that
 $\underline {\phi }$
and
$\underline {\phi }$
and
 $\overline {\phi }$
model interval arithmetic for
$\overline {\phi }$
model interval arithmetic for
 $\Phi$
. It is straightforward to state Assumption 2.1, with two different neural network classes, adopting this detail into our result. However, in the interest of keeping things short and clean, we do not make this distinction.
$\Phi$
. It is straightforward to state Assumption 2.1, with two different neural network classes, adopting this detail into our result. However, in the interest of keeping things short and clean, we do not make this distinction.
3. Table of notation
For an easier reference of the key mathematical objects, and to improve the readability of the paper, we include a table of notation.

4. Main theorem
4.1. Preliminaries
We introduce some notation on how to encode the parameters of a neural network
 $\Phi$
. Given the number of layers
$\Phi$
. Given the number of layers
 $K \in \mathbb{N}$
, and some pre-fixed dimensions
$K \in \mathbb{N}$
, and some pre-fixed dimensions
 $N_0,N_1, \ldots , N_K \in \mathbb{N}$
, we define
$N_0,N_1, \ldots , N_K \in \mathbb{N}$
, we define
 $\theta _{\Phi }$
to be the collection
$\theta _{\Phi }$
to be the collection
 \begin{align} \theta _{\Phi } = \bigcup _{k = 0}^K \left\{b^{(k)}_j\right\}_{j = 1}^{j =N_k} \cup \left\{W^{(k)}_{i,j}\right\}_{i,j = 1}^{i = N_{k-1}, j = N_{k}}. \end{align}
\begin{align} \theta _{\Phi } = \bigcup _{k = 0}^K \left\{b^{(k)}_j\right\}_{j = 1}^{j =N_k} \cup \left\{W^{(k)}_{i,j}\right\}_{i,j = 1}^{i = N_{k-1}, j = N_{k}}. \end{align}
In other words,
 $\theta _{\Phi }$
stores the information about the entries of the weights and the biases of the neural network
$\theta _{\Phi }$
stores the information about the entries of the weights and the biases of the neural network
 $\Phi$
with pre-fixed dimensions. With this in place, we give the following more precise statement about our objective. For a given class
$\Phi$
with pre-fixed dimensions. With this in place, we give the following more precise statement about our objective. For a given class
 ${\mathcal{N} \mathcal{N}}_{\ell }$
that satisfies Assumption 2.1, a given model class
${\mathcal{N} \mathcal{N}}_{\ell }$
that satisfies Assumption 2.1, a given model class
 ${\mathcal{U}}_1$
, a parameter
${\mathcal{U}}_1$
, a parameter
 $\beta \gt 0$
, a collection
$\beta \gt 0$
, a collection
 \begin{align} \Omega \subseteq \{ ({\mathcal{T}}, \theta _{\Phi }) \: | \: {\mathcal{T}} \in T_{\ell ,\mathcal{U}_1}, \; \theta _{\Phi } \; \text{parameters of} \; \Phi , \; \text{and} \; \Phi \in \mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })\}, \end{align}
\begin{align} \Omega \subseteq \{ ({\mathcal{T}}, \theta _{\Phi }) \: | \: {\mathcal{T}} \in T_{\ell ,\mathcal{U}_1}, \; \theta _{\Phi } \; \text{parameters of} \; \Phi , \; \text{and} \; \Phi \in \mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })\}, \end{align}
and a mapping
 $\Xi _{\beta } \colon \Omega \rightrightarrows \mathcal{NN}_{\Phi }^u \times \mathcal{NN}_{\Phi }^o$
, given by
$\Xi _{\beta } \colon \Omega \rightrightarrows \mathcal{NN}_{\Phi }^u \times \mathcal{NN}_{\Phi }^o$
, given by
 \begin{equation} \Xi _{\beta }(\mathcal{T}, \theta _{\Phi }) =\mathop{argmin} \limits_{\underline {\psi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\psi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi }), \end{equation}
\begin{equation} \Xi _{\beta }(\mathcal{T}, \theta _{\Phi }) =\mathop{argmin} \limits_{\underline {\psi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\psi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi }), \end{equation}
our goal is to investigate whether we can compute an element
 $(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }(\mathcal{T}, \theta _{\Phi })$
for each pair
$(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }(\mathcal{T}, \theta _{\Phi })$
for each pair
 $(\mathcal{T}, \theta _{\Phi }) \in \Omega$
, when reading inexact inputs. Throughout the paper, we will assume that
$(\mathcal{T}, \theta _{\Phi }) \in \Omega$
, when reading inexact inputs. Throughout the paper, we will assume that
 $\Xi _{\beta }(\mathcal{T}, \theta _{\Phi }) \neq \emptyset$
. This is obvious for standard choices of the non-linear
$\Xi _{\beta }(\mathcal{T}, \theta _{\Phi }) \neq \emptyset$
. This is obvious for standard choices of the non-linear
 $\sigma$
, because for standard choices of
$\sigma$
, because for standard choices of
 $\sigma$
the weights
$\sigma$
the weights
 $W^{(k)}$
and the biases
$W^{(k)}$
and the biases
 $b^{(k)}$
do not tend to
$b^{(k)}$
do not tend to
 $\infty$
or
$\infty$
or
 $-\infty$
as we minimise
$-\infty$
as we minimise
 $F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi })$
.
$F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi })$
.
We say that an algorithm
 $\Gamma \,:\, \Omega \to \mathcal{NN}_{\Phi }^u \times \mathcal{NN}_{\Phi }^o$
approximates an optimal pair of interval neural networks
$\Gamma \,:\, \Omega \to \mathcal{NN}_{\Phi }^u \times \mathcal{NN}_{\Phi }^o$
approximates an optimal pair of interval neural networks
 $(\underline {\phi },\overline {\phi }) \in \mathcal{NN}_{\Phi }^u \times \mathcal{NN}_{\Phi }^o$
to accuracy
$(\underline {\phi },\overline {\phi }) \in \mathcal{NN}_{\Phi }^u \times \mathcal{NN}_{\Phi }^o$
to accuracy
 $\delta$
, for a training set
$\delta$
, for a training set
 $\mathcal{T}$
, if
$\mathcal{T}$
, if
 \begin{align*} \text{dist}_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),\Xi _{\beta }({\mathcal{T}},\theta _{\Phi })) \,:\!=\, \inf _{(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }({\mathcal{T}},\theta _{\Phi })}d_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),(\underline {\phi },\overline {\phi })) \leq \delta , \end{align*}
\begin{align*} \text{dist}_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),\Xi _{\beta }({\mathcal{T}},\theta _{\Phi })) \,:\!=\, \inf _{(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }({\mathcal{T}},\theta _{\Phi })}d_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),(\underline {\phi },\overline {\phi })) \leq \delta , \end{align*}
with
 \begin{align} d_{{\mathcal{T}}} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) = \max \left \{ \sup _{y \in \pi _2({\mathcal{T}})} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in \pi _2({\mathcal{T}})} \| \underline {\phi }(y) - \underline {\psi }(y) \|_2^2 \right \}, \end{align}
\begin{align} d_{{\mathcal{T}}} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) = \max \left \{ \sup _{y \in \pi _2({\mathcal{T}})} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in \pi _2({\mathcal{T}})} \| \underline {\phi }(y) - \underline {\psi }(y) \|_2^2 \right \}, \end{align}
where
 $\pi _2({\mathcal{T}}) = \{y \in {\mathbb{R}}^m \: : \: (x,y) \in {\mathcal{T}} \}$
.
$\pi _2({\mathcal{T}}) = \{y \in {\mathbb{R}}^m \: : \: (x,y) \in {\mathcal{T}} \}$
.
4.2. Inexactness and the main theorem
For completeness, we give an intuitive explanation of why we need to consider inexact input and what we mean by inexact input. Due to the discrete nature of computers, a training set
 $\mathcal{T} = \{(x^{(j)},y^{(j)})\}_{j=1}^r$
can often not be represented exactly on a computer, because the only numbers that are exactly representable are a subset of the dyadic rationals given by
$\mathcal{T} = \{(x^{(j)},y^{(j)})\}_{j=1}^r$
can often not be represented exactly on a computer, because the only numbers that are exactly representable are a subset of the dyadic rationals given by
 ${\mathbb{D}} = \{a2^{-j} \: : \: a \in \mathbb{Z}, \: j \in \mathbb{N} \}$
. The matrix
${\mathbb{D}} = \{a2^{-j} \: : \: a \in \mathbb{Z}, \: j \in \mathbb{N} \}$
. The matrix
 $A$
could, for example, have irrational entries, which happens in many real-world applications. The entries of
$A$
could, for example, have irrational entries, which happens in many real-world applications. The entries of
 $A$
can only be approximated in finite base-2 arithmetic, giving rise to round-off approximations, and an inexact representation of the elements in the training set
$A$
can only be approximated in finite base-2 arithmetic, giving rise to round-off approximations, and an inexact representation of the elements in the training set
 $\mathcal{T}$
.
$\mathcal{T}$
.
Thus, for each choice of training set
 $\mathcal{T}$
, we assume that the algorithm has access to a sequence of dyadic training sets
$\mathcal{T}$
, we assume that the algorithm has access to a sequence of dyadic training sets
 $\{\mathcal{T}_n\}_{n\in \mathbb{N}}$
, where for each
$\{\mathcal{T}_n\}_{n\in \mathbb{N}}$
, where for each
 $(x,y) \in \mathcal{T}$
and
$(x,y) \in \mathcal{T}$
and
 $n\in \mathbb{N}$
, there is a pair
$n\in \mathbb{N}$
, there is a pair
 $(x^n,y^n) \in \mathcal{T}_n \subset \mathbb{{\mathbb{D}}}^N\times \mathbb{{\mathbb{D}}}^m$
, such that for all
$(x^n,y^n) \in \mathcal{T}_n \subset \mathbb{{\mathbb{D}}}^N\times \mathbb{{\mathbb{D}}}^m$
, such that for all
 $i = 1, \ldots , N$
and
$i = 1, \ldots , N$
and
 $j = 1, \ldots , m$
, we have that
$j = 1, \ldots , m$
, we have that
 $|x^n_i - x_i| \leq 2^{-n}$
and that
$|x^n_i - x_i| \leq 2^{-n}$
and that
 $|y^n_j - y_j| \leq 2^{-n}$
. With
$|y^n_j - y_j| \leq 2^{-n}$
. With
 $n(N) = n + \lceil \log _2(\sqrt {N}) \rceil$
and
$n(N) = n + \lceil \log _2(\sqrt {N}) \rceil$
and
 $n(m) = n + \lceil \log _2(\sqrt {m}) \rceil$
we then get that
$n(m) = n + \lceil \log _2(\sqrt {m}) \rceil$
we then get that
 \begin{equation*} \|x^{n(N)} - x\|_{2} \leq 2^{-n} \quad \text{ and } \quad \|y^{n(m)}- y\|_{2}\leq 2^{-n}.\end{equation*}
\begin{equation*} \|x^{n(N)} - x\|_{2} \leq 2^{-n} \quad \text{ and } \quad \|y^{n(m)}- y\|_{2}\leq 2^{-n}.\end{equation*}
Similarly, for each parameter
 $\theta _{\Phi }^h$
for
$\theta _{\Phi }^h$
for
 $h \in H$
, where
$h \in H$
, where
 $H$
is some finite index set for the parameters of
$H$
is some finite index set for the parameters of
 $\Phi$
, there is a dyadic sequence of numbers
$\Phi$
, there is a dyadic sequence of numbers
 $\{\theta _{\Phi }^{h,n}\}_{n\in \mathbb{N}}$
, such that for each
$\{\theta _{\Phi }^{h,n}\}_{n\in \mathbb{N}}$
, such that for each
 $n\in \mathbb{N}$
we have that
$n\in \mathbb{N}$
we have that
 $|\theta _{\Phi }^{h,n} - \theta _{\Phi }^h | \leq 2^{-n}$
. Finally, we require that the approximations satisfy the same well-posedness assumptions as
$|\theta _{\Phi }^{h,n} - \theta _{\Phi }^h | \leq 2^{-n}$
. Finally, we require that the approximations satisfy the same well-posedness assumptions as
 $\mathcal{T}$
and
$\mathcal{T}$
and
 $\Phi$
. More specifically, that
$\Phi$
. More specifically, that
 ${\mathcal{T}}_n \in T_{\ell ,{\mathcal{U}}_1}$
for each
${\mathcal{T}}_n \in T_{\ell ,{\mathcal{U}}_1}$
for each
 $n \in \mathbb{N}$
, and that the neural network
$n \in \mathbb{N}$
, and that the neural network
 $\Phi _n$
, represented by the parameters
$\Phi _n$
, represented by the parameters
 $\{\theta _{\Phi }^{h,n}\}_{h \in H}$
, satisfies
$\{\theta _{\Phi }^{h,n}\}_{h \in H}$
, satisfies
 $\Phi _n \in \mathcal{W}({\mathcal{T}}_n,{\mathcal{N} \mathcal{N}}_{\ell })$
for each
$\Phi _n \in \mathcal{W}({\mathcal{T}}_n,{\mathcal{N} \mathcal{N}}_{\ell })$
for each
 $n \in \mathbb{N}$
.
$n \in \mathbb{N}$
.
We require that a successful algorithm should work on any approximating sequence of the form
 $(\{{\mathcal{T}}_n\}_{n \in \mathbb{N}},\{\theta _{\Phi _n}\}_{n\in \mathbb{N}})$
. Note that this extended computational model accepting inexact input is standard and can be found in many areas of the mathematical literature, and we mention only a small subset here including the work in [Reference Cucker and Smale33, Reference Fefferman and Klartag39, Reference Gazdag and Hansen41, Reference Ko50, Reference Turing72].
$(\{{\mathcal{T}}_n\}_{n \in \mathbb{N}},\{\theta _{\Phi _n}\}_{n\in \mathbb{N}})$
. Note that this extended computational model accepting inexact input is standard and can be found in many areas of the mathematical literature, and we mention only a small subset here including the work in [Reference Cucker and Smale33, Reference Fefferman and Klartag39, Reference Gazdag and Hansen41, Reference Ko50, Reference Turing72].
Remark 4.1. The above model means that for each training set
 $\mathcal{T} = \{(x^{(j)},y^{(j)})\}_{j=1}^r$
and for each pre-trained neural network
$\mathcal{T} = \{(x^{(j)},y^{(j)})\}_{j=1}^r$
and for each pre-trained neural network
 $\Phi \in \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
, we have infinitely many collections of approximate sequences
$\Phi \in \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
, we have infinitely many collections of approximate sequences
 \begin{equation} (\mathcal{\tilde T},\tilde {\theta }_{\Phi }) = \big(\left\{\left\{\left(x^{(j),n},y^{(j),n}\right)\right\}_{n\in \mathbb{N}}\right\}_{j = 1}^r, \left\{\left\{\theta _{\Phi }^{h,n}\right\}_{n\in \mathbb{N}}\right\}_{h \in H}\big) \end{equation}
\begin{equation} (\mathcal{\tilde T},\tilde {\theta }_{\Phi }) = \big(\left\{\left\{\left(x^{(j),n},y^{(j),n}\right)\right\}_{n\in \mathbb{N}}\right\}_{j = 1}^r, \left\{\left\{\theta _{\Phi }^{h,n}\right\}_{n\in \mathbb{N}}\right\}_{h \in H}\big) \end{equation}
as described above. A sequence of approximations is provided to the algorithm through an ‘oracle’. For example, in the case of a Turing machine [Reference Turing72], this would be through an oracle input tape (see [Reference Ko50] for the standard setup), or in the case of a Blum–Shub–Smale (BSS) machine [Reference Blum, Cucker, Shub and Smale19], this would be through an oracle node. The algorithm can thus ask for an approximation to any given accuracy as described above and use as many queries as desired. We want to emphasise that our results hold regardless of the computational model for the ‘oracle’. In particular, all our results hold in the Markov model based on the Markov algorithm [Reference Salomaa, Press, Rota, Doran, Lam, Flajolet, Ismail and Lutwak66] – that is, when the inexact input is required to be computable, in particular when
 $\{(x^{(j),n},y^{(j),n})\}_{n\in \mathbb{N}}$
and
$\{(x^{(j),n},y^{(j),n})\}_{n\in \mathbb{N}}$
and
 $\{\theta _{\Phi }^{h,n}\}_{n\in \mathbb{N}}$
are computable sequences for each
$\{\theta _{\Phi }^{h,n}\}_{n\in \mathbb{N}}$
are computable sequences for each
 $j = 1,\ldots , r$
and
$j = 1,\ldots , r$
and
 $h \in H$
.
$h \in H$
.
We end this section by informally stating the main theorem of this paper. See Theorem 6.8 for the detailed statement.
Theorem 4.2 (Non-existence of algorithms). Let
 $m,N \in \mathbb{N}$
with
$m,N \in \mathbb{N}$
with
 $N \geq 2$
, and let
$N \geq 2$
, and let
 $A \in {\mathbb{R}}^{m\times N}$
be such that
$A \in {\mathbb{R}}^{m\times N}$
be such that
 $1\leq \mathrm{rank}(A) \lt N$
. Let
$1\leq \mathrm{rank}(A) \lt N$
. Let
 $\ell \geq 2$
,
$\ell \geq 2$
,
 $\kappa \in (0,1/8)$
and let
$\kappa \in (0,1/8)$
and let
 ${\mathcal{N} \mathcal{N}}_{\ell }$
be a class of neural networks that satisfy Assumption 2.1. Then, for any
${\mathcal{N} \mathcal{N}}_{\ell }$
be a class of neural networks that satisfy Assumption 2.1. Then, for any
 $\beta \in (0, \sqrt {\kappa }/(4\sqrt {2N}))$
, there exist infinitely many model classes
$\beta \in (0, \sqrt {\kappa }/(4\sqrt {2N}))$
, there exist infinitely many model classes
 ${\mathcal{U}}_1 \subseteq B_1^N(0)$
, and for each model class, infinitely many collections
${\mathcal{U}}_1 \subseteq B_1^N(0)$
, and for each model class, infinitely many collections
 \begin{align*} \Omega = \{({\mathcal{T}}, \theta _{\Phi }) \: : \: {\mathcal{T}} \in T_{\ell , {\mathcal{U}}_1} \: \text{and} \: \; \Phi \in \mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })\} \end{align*}
\begin{align*} \Omega = \{({\mathcal{T}}, \theta _{\Phi }) \: : \: {\mathcal{T}} \in T_{\ell , {\mathcal{U}}_1} \: \text{and} \: \; \Phi \in \mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })\} \end{align*}
of training sets and corresponding pre-trained neural networks, such that no algorithm, even randomised (with probability
 $p \geq 1/2$
), can approximate an optimal pair of interval neural networks
$p \geq 1/2$
), can approximate an optimal pair of interval neural networks
 $(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }({\mathcal{T}}, \theta _{\Phi })$
for all elements
$(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }({\mathcal{T}}, \theta _{\Phi })$
for all elements
 $({\mathcal{T}},\theta _{\Phi }) \in \Omega$
to accuracy
$({\mathcal{T}},\theta _{\Phi }) \in \Omega$
to accuracy
 $\kappa /2$
, when reading inexact input.
$\kappa /2$
, when reading inexact input.
Remark 4.3 (Possible extensions of Theorem 4.2). In order to keep the paper conceptually clear and close to the original reference [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61], we have chosen to optimise over the the class of neural networks in Theorem 4.2, in the sense that the class
 ${\mathcal{N} \mathcal{N}}_{\ell }$
consists of neural networks, and we have chosen to keep the objective function
${\mathcal{N} \mathcal{N}}_{\ell }$
consists of neural networks, and we have chosen to keep the objective function
 $F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi })$
, that gives rise to
$F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi })$
, that gives rise to
 $\Xi _{\beta }({\mathcal{T}}, \theta _{\Phi })$
, as described in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61]. However, we would like to point out that Theorem 4.2 can be proved for both more general function classes, replacing
$\Xi _{\beta }({\mathcal{T}}, \theta _{\Phi })$
, as described in [Reference Oala, Heiz, Macdonald, Marz, Samek and Kutyniok61]. However, we would like to point out that Theorem 4.2 can be proved for both more general function classes, replacing
 ${\mathcal{N} \mathcal{N}}_{\ell }$
, and for more general objective functions, replacing
${\mathcal{N} \mathcal{N}}_{\ell }$
, and for more general objective functions, replacing
 $F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi })$
. More specifically, the class
$F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi })$
. More specifically, the class
 ${\mathcal{N} \mathcal{N}}_{\ell }$
can be replaced by any class of computable functions satisfying Assumption 2.1 for which the set of measurements
${\mathcal{N} \mathcal{N}}_{\ell }$
can be replaced by any class of computable functions satisfying Assumption 2.1 for which the set of measurements
 $\Delta$
, as described in section 6, can be defined in a way that satisfies the assumptions in Proposition 7.4. The function
$\Delta$
, as described in section 6, can be defined in a way that satisfies the assumptions in Proposition 7.4. The function
 $F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi })$
, defined in Eq. (2.4), can be replaced by any function
$F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi })$
, defined in Eq. (2.4), can be replaced by any function
 $G_{\mathcal{T},\beta , p,q}(\underline {\psi },\overline {\psi })$
defined by
$G_{\mathcal{T},\beta , p,q}(\underline {\psi },\overline {\psi })$
defined by
 \begin{equation} G_{{\mathcal{T}}, \beta ,p,q}(\underline {\phi },\overline {\phi }) \,:\!=\, \sum _{(x,y) \in {\mathcal{T}}} \| \max \{x - \overline {\phi }(y), 0 \} \|_p^p + \| \max \{ \underline {\phi }(y) - x, 0 \} \|_p^p + \beta \| \overline {\phi }(y) - \underline {\phi }(y) \|_q, \end{equation}
\begin{equation} G_{{\mathcal{T}}, \beta ,p,q}(\underline {\phi },\overline {\phi }) \,:\!=\, \sum _{(x,y) \in {\mathcal{T}}} \| \max \{x - \overline {\phi }(y), 0 \} \|_p^p + \| \max \{ \underline {\phi }(y) - x, 0 \} \|_p^p + \beta \| \overline {\phi }(y) - \underline {\phi }(y) \|_q, \end{equation}
for any
 $p,q \in \mathbb{N}$
. In other words, the norms in Eq. (2.4) can be generalised to arbitrary
$p,q \in \mathbb{N}$
. In other words, the norms in Eq. (2.4) can be generalised to arbitrary
 $l_p$
and
$l_p$
and
 $l_q$
-norms.
$l_q$
-norms.
4.3. Consequences of the main theorem
Theorem 4.2 tells us that there exists classes of training sets
 $\Omega$
, such there exists no algorithm, even randomised, that can approximate an optimal pair of interval neural networks, for each training set
$\Omega$
, such there exists no algorithm, even randomised, that can approximate an optimal pair of interval neural networks, for each training set
 ${\mathcal{T}} \in \Omega$
. Moreover, that this happens even when we are given a pre-trained neural network
${\mathcal{T}} \in \Omega$
. Moreover, that this happens even when we are given a pre-trained neural network
 $\Phi _{{\mathcal{T}}}$
, that is optimal for
$\Phi _{{\mathcal{T}}}$
, that is optimal for
 $\mathcal{T}$
, for each
$\mathcal{T}$
, for each
 ${\mathcal{T}} \in \Omega$
. The problem of constructing an optimal
${\mathcal{T}} \in \Omega$
. The problem of constructing an optimal
 $\Phi _{{\mathcal{T}}}$
for each
$\Phi _{{\mathcal{T}}}$
for each
 ${\mathcal{T}} \in \Omega$
is non-computable in itself [Reference Gazdag and Hansen41], but Theorem 4.2 shows that, even if we had an oracle providing an optimal solution
${\mathcal{T}} \in \Omega$
is non-computable in itself [Reference Gazdag and Hansen41], but Theorem 4.2 shows that, even if we had an oracle providing an optimal solution
 $\Phi _{{\mathcal{T}}}$
for each
$\Phi _{{\mathcal{T}}}$
for each
 ${\mathcal{T}} \in \Omega$
, there are still cases where we would not be able to compute a correct uncertainty score for the predictions of
${\mathcal{T}} \in \Omega$
, there are still cases where we would not be able to compute a correct uncertainty score for the predictions of
 $\Phi _{{\mathcal{T}}}$
in form of interval neural networks
$\Phi _{{\mathcal{T}}}$
in form of interval neural networks
 $\underline {\phi }$
and
$\underline {\phi }$
and
 $\overline {\phi }$
. Recall the projections
$\overline {\phi }$
. Recall the projections
 $\pi _1({\mathcal{T}})$
and
$\pi _1({\mathcal{T}})$
and
 $\pi _2({\mathcal{T}})$
onto the coordinates of a training set
$\pi _2({\mathcal{T}})$
onto the coordinates of a training set
 $\mathcal{T}$
from Eq. (2.5), and recall that the goal of minimising Eq. (2.4) is to provide the sharpest possible bounds for the set
$\mathcal{T}$
from Eq. (2.5), and recall that the goal of minimising Eq. (2.4) is to provide the sharpest possible bounds for the set
 $X_y \,:\!=\, \{x \in \pi _1({\mathcal{T}}) \: : \: y = Ax \}$
for each
$X_y \,:\!=\, \{x \in \pi _1({\mathcal{T}}) \: : \: y = Ax \}$
for each
 $y \in \pi _2({\mathcal{T}})$
, in the sense that the interval
$y \in \pi _2({\mathcal{T}})$
, in the sense that the interval
 $[\underline {\phi }(y),\overline {\phi }(y)]$
should be the smallest possible with the property that
$[\underline {\phi }(y),\overline {\phi }(y)]$
should be the smallest possible with the property that
 $\underline {\phi }(y) \leq x \leq \overline {\phi }(y)$
for all
$\underline {\phi }(y) \leq x \leq \overline {\phi }(y)$
for all
 $x \in X_y$
. Then the failure of constructing an optimal pair of interval neural networks can lead to different types of errors:
$x \in X_y$
. Then the failure of constructing an optimal pair of interval neural networks can lead to different types of errors:
-
(1) (Wrong certainty prediction.) In the case where
$X_y = \{x^1, x^2\}$
with
$x^1 \neq x^2$
for a
$y \in \pi _2({\mathcal{T}})$
, the reading of inexact input could lead the computer to interpret the pairs
$(x^1,y),(x^2,y) \in {\mathcal{T}}$
as two pairs
$(x^1,y^1)$
and
$(x^2,y^2)$
with
$y^1 \neq y^2$
. Minimising Eq. (2.4) with this interpretation would yield that
$\underline {\phi }(y^1) = \overline {\phi }(y^1) = x^1$
and that
$\underline {\phi }(y^2) = \overline {\phi }(y^2) = x^2$
, yielding an uncertainty score of zero for both
$y^1$
and
$y^2$
, whereas an optimal solution should give non-zero uncertainty score to the element
$y$
instead. In other words, inexact representations might lead us to think that there is no uncertainty in our predictions, even when there is uncertainty present. -
(2) (Failure of sharpness). On the other hand, the inexact reading of inputs could result in the computer interpreting two distinct points
$(x^1,y^1), (x^2,y^2) \in {\mathcal{T}}$
with
$y^1 \neq y^2$
as pairs
$(x^1,y),(x^2,y)$
. In this case, the algorithm over-quantifies the uncertainty, in the sense that it will provide a non-zero uncertainty score for the element
$y$
, whereas the correct prediction would be zero uncertainty scores for the elements
$y_1$
and
$y_2$
, respectively. As a result, the total uncertainty score will increase and we will think that our prediction is less certain than it is. -
(3) (Data poisoning). Data poisoning is a phenomenon where an attacker subtly alters a portion of the training data, often in an imperceptible manner, leading to the trained system behaving unreliably for specific inputs. The above instabilities demonstrate that certain inputs exist such that even minimal perturbations to the training dataset can result in significantly different interval neural networks when using standard training procedures.


















To make matters even worse, we will have no way of detecting whether we are in failure mode
 $(1)$
or
$(1)$
or
 $(2)$
above, or in other words whether we in general should expect that there is more, or less, uncertainty than what our uncertainty estimation predicts.
$(2)$
above, or in other words whether we in general should expect that there is more, or less, uncertainty than what our uncertainty estimation predicts.
5. Connection to previous work
Generalised hardness of approximation and the mathematics behind the SCI hierarchy. The results in this paper are part of the programme on the limitations of AI, which is the topic of the 18th problem on Smale’s list of mathematical problems for the 21st century [Reference Smale, Arnold, Atiyah, Lax and Mazur69]. This paper specifically connects the limitations of AI to the instability of neural networks and the challenges of reliably quantifying uncertainty computationally. It achieves this by establishing lower bounds on the ‘breakdown epsilon’ for the problem of computing interval neural networks. The concept of ‘breakdown epsilon’ stems from generalised hardness of approximation [Reference Bastounis, Hansen and Vlačić11, Reference Colbrook, Antun and Hansen31, Reference Gazdag and Hansen41] (and is crucial in Proposition 7.4) which is part of the mathematics behind the SCI hierarchy. See also Problem 5 (J. Lagarias) in [Reference Fefferman, Hansen and Jitomirskaya38] for a discussion on GHA and optimisation. The prerequisites in Section 7.2 as well as Definition 6.6 stem from [Reference Bastounis, Hansen and Vlačić11] and the SCI hierarchy, introduced in [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel12, Reference Hansen45] and further developed in [Reference Ben-Artzi, Marletta and Rösler14, Reference Ben-Artzi, Marletta and Rösler15, Reference Colbrook, Horning and Townsend30, Reference Colbrook and Hansen32], as well as [Reference Ben-Artzi, Hansen, Nevanlinna and Seidel13, Reference Hansen and Nevanlinna46]. Our results follow this tradition and rely on the developments in this area. The SCI hierarchy is intrinsically connected to S. Smale’s [Reference Doyle and McMullen36, Reference Smale67, Reference Smale68] foundational programme on computational mathematics and scientific computing, see [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel12] for details.
Instability in AI. Our findings are closely tied to the phenomenon of instability in AI methodologies. When trained to solve problems across virtually all applications, neural networks exhibit universal instability (non-robustness) [Reference Antun, Renna, Poon, Adcock and Hansen5, Reference Choi28, Reference Finlayson, Bowers, Ito, Zittrain, Beam and Kohane40, Reference Heaven47, Reference Moosavi-Dezfooli, Fawzi, Fawzi and Frossard57]. Early research on neural network instability can be found here [Reference Moosavi-Dezfooli, Fawzi, Fawzi and Frossard57, Reference Moosavi-Dezfooli, Fawzi and Frossard58, Reference Szegedy, Zaremba, Sutskever, Bruna, Erhan, Goodfellow and Fergus71] (see also [Reference Liu and Hansen52] and the references therein). The key link between our results and instabilities in AI is that estimating uncertainty of unstable systems may itself be subject to instabilities that will affect reliable computations. Our research also aligns closely with the following contributions [Reference Adcock and Dexter1, Reference Antun, Renna, Poon, Adcock and Hansen5, Reference Bastounis, Hansen and Vlacic10]. See also recent advancements in this domain [Reference Bungert, García Trillos and Murray23, Reference Tyukin, Higham and Gorban73, Reference Tyukin, Higham, Gorban and Woldegeorgis74, Reference Wang, Si, Blanchet and Zhou77].
Robust optimisation. Our results and the concept of GHA are directly linked to robust optimisation and the seminal work by Ben-Tal, El Ghaoui, and Nemirovski [Reference Ben-Tal, El Ghaoui and Nemirovski16, Reference Ben-Tal and Nemirovski17, Reference Nemirovski59, Reference Nemirovskii60]. Specifically, GHA is essential for any robust optimisation theory aimed at computing minimisers of both convex and non-convex optimisation problems. Our work illustrates the delicate issues occurring when AI, instability and robust optimisation meet uncertainty quantification.
Existence vs computability of NNs. There is an extensive literature on existence results of neural networks (NNs) [Reference Bölcskei, Grohs, Kutyniok and Petersen20, Reference Petersen and Voigtlaender63, Reference Yarotsky79]. See [Reference Voigtlaender76] for recent extensions of the universal approximation theorem, the comprehensive review [Reference Pinkus64] on classical results, and [Reference DeVore, Hanin and Petrova34] for a survey on more modern approaches. However, as demonstrated in [Reference Colbrook, Antun and Hansen31], only a small subset of theoretically proven NNs can be algorithmically computed. This is a similar phenomenon to the results in this paper: the interval NNs may exist, but computing them to provide reasonable uncertainty bounds may be impossible. We mention in passing that within the computational framework proposed in [Reference Chambolle26, Reference Chambolle and Pock27], the results of [Reference Colbrook, Antun and Hansen31] further establish that stable and accurate NNs are computable under specific assumptions.
6. Mathematical preliminaries from the SCI hierarchy
6.1. Computational problems and
$\Delta _1$
-information

We formulate our results in the language of the SCI hierarchy. The SCI hierarchy is a mathematical framework designed to classify the intrinsic difficulty of different computational problems found in scientific computing. As its theory is now extensive, we only cite a limited number of results [Reference Ben-Artzi, Colbrook, Hansen, Nevanlinna and Seidel12, Reference Ben-Artzi, Hansen, Nevanlinna and Seidel13, Reference Ben-Artzi, Marletta and Rösler15, Reference Colbrook, Horning and Townsend30, Reference Colbrook, Antun and Hansen31, Reference Colbrook and Hansen32, Reference Hansen45, Reference Hansen and Nevanlinna46]. For completeness, we include the definitions from the SCI hierarchy that are needed for our statements and proofs, and we follow the lines of [Reference Bastounis, Hansen and Vlačić11] in our presentation.
The most basic building block in the SCI hierarchy is the notion of a computational problem. We start by abstractly defining the concept of a computational problem, and thereafter, we describe how computing interval neural networks can be embedded into this language.
Definition 6.1 (Computational problem [Reference Bastounis, Hansen and Vlačić11]). Let
 $\Omega$
be some set, which we call the domain or input set. Let
$\Omega$
be some set, which we call the domain or input set. Let
 $\Lambda$
be a set of complex-valued functions on
$\Lambda$
be a set of complex-valued functions on
 $\Omega$
such that for
$\Omega$
such that for
 $\iota _1, \iota _2 \in \Omega$
, then
$\iota _1, \iota _2 \in \Omega$
, then
 $\iota _1 = \iota _2$
if and only if
$\iota _1 = \iota _2$
if and only if
 $f(\iota _1) = f(\iota _2)$
for all
$f(\iota _1) = f(\iota _2)$
for all
 $f \in \Lambda$
, called an evaluation set. Let
$f \in \Lambda$
, called an evaluation set. Let
 $(\mathcal{M},d)$
be a metric space, and finally let
$(\mathcal{M},d)$
be a metric space, and finally let
 $\Xi \,:\,\Omega \to \mathcal{M}$
be a function which we call the problem function. We call the collection
$\Xi \,:\,\Omega \to \mathcal{M}$
be a function which we call the problem function. We call the collection
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
a computational problem.
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
a computational problem.
In the above definition, the function
 $\Xi \colon \Omega \to \mathcal{M}$
is the problem function which gives rise to the computational problem. It is this function we seek to approximate/compute. The set
$\Xi \colon \Omega \to \mathcal{M}$
is the problem function which gives rise to the computational problem. It is this function we seek to approximate/compute. The set
 $\Omega$
is the domain of
$\Omega$
is the domain of
 $\Xi$
and the metric space
$\Xi$
and the metric space
 $(\mathcal{M},d)$
is the range of this function. The set
$(\mathcal{M},d)$
is the range of this function. The set
 $\Lambda$
describes which type of information we can acquire about the input to
$\Lambda$
describes which type of information we can acquire about the input to
 $\Xi$
. It is this information which can be accessed by an algorithm. For convenience, we throughout the manuscript restrict our attention to sets
$\Xi$
. It is this information which can be accessed by an algorithm. For convenience, we throughout the manuscript restrict our attention to sets
 $\Lambda$
that are finite.
$\Lambda$
that are finite.
Recall that for a given training set size
 $\ell \geq 2$
, model class
$\ell \geq 2$
, model class
 $\mathcal{U}_1\subset B_{1}^{N}(0)$
, and matrix
$\mathcal{U}_1\subset B_{1}^{N}(0)$
, and matrix
 $A \in {\mathbb{R}}^{m\times N}$
, we have that
$A \in {\mathbb{R}}^{m\times N}$
, we have that
 \begin{equation} T_{\ell ,\mathcal{U}_1} = \{ \{(x^{(1)},Ax^{1}),\ldots , (x^{(\ell )}, Ax^{(\ell )})\}\subset \mathcal{U}_1\times A(\mathcal{U}_1) \,:\, x^{(1)}, \ldots , x^{(\ell )} \in \mathcal{U}_1 \} \end{equation}
\begin{equation} T_{\ell ,\mathcal{U}_1} = \{ \{(x^{(1)},Ax^{1}),\ldots , (x^{(\ell )}, Ax^{(\ell )})\}\subset \mathcal{U}_1\times A(\mathcal{U}_1) \,:\, x^{(1)}, \ldots , x^{(\ell )} \in \mathcal{U}_1 \} \end{equation}
denotes the class of all training sets of size
 $\ell$
with respect to the model class
$\ell$
with respect to the model class
 $\mathcal{U}_1$
. Then, for a given class
$\mathcal{U}_1$
. Then, for a given class
 ${\mathcal{N} \mathcal{N}}_{\ell }$
of neural networks that satisfy Assumption 2.1, the domain
${\mathcal{N} \mathcal{N}}_{\ell }$
of neural networks that satisfy Assumption 2.1, the domain
 $\Omega$
of our computational problem is a collection of pairs of such training sets and the corresponding parameters of a pre-trained neural network
$\Omega$
of our computational problem is a collection of pairs of such training sets and the corresponding parameters of a pre-trained neural network
 $\Phi \in \mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })$
, where
$\Phi \in \mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })$
, where
 $\mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })$
is as defined in Eq. (2.8). More precisely,
$\mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })$
is as defined in Eq. (2.8). More precisely,
 \begin{align*} \Omega \subseteq \{ ({\mathcal{T}}, \theta _{\Phi }) \: | \: {\mathcal{T}} \in T_{\ell ,\mathcal{U}_1}, \; \theta _{\Phi } \; \text{parameters of} \; \Phi , \; \text{and} \; \Phi \in \mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })\}. \end{align*}
\begin{align*} \Omega \subseteq \{ ({\mathcal{T}}, \theta _{\Phi }) \: | \: {\mathcal{T}} \in T_{\ell ,\mathcal{U}_1}, \; \theta _{\Phi } \; \text{parameters of} \; \Phi , \; \text{and} \; \Phi \in \mathcal{W}({\mathcal{T}}, {\mathcal{N} \mathcal{N}}_{\ell })\}. \end{align*}
For any fixed
 $\beta \gt 0$
, we then seek to compute a minimisation of (2.4) for neural networks
$\beta \gt 0$
, we then seek to compute a minimisation of (2.4) for neural networks
 $\underline {\phi } \in \mathcal{NN}_{\Phi }^u$
and
$\underline {\phi } \in \mathcal{NN}_{\Phi }^u$
and
 $\overline {\phi } \in \mathcal{NN}_{\Phi }^o$
. That is, for a given domain
$\overline {\phi } \in \mathcal{NN}_{\Phi }^o$
. That is, for a given domain
 $\Omega$
of training sets and pre-trained neural networks, our problem function
$\Omega$
of training sets and pre-trained neural networks, our problem function
 $\Xi _{\beta } \colon \Omega \rightrightarrows \mathcal{M}$
, with
$\Xi _{\beta } \colon \Omega \rightrightarrows \mathcal{M}$
, with
 ${\mathcal{M}} \,:\!=\, \mathcal{NN}^u_{{\mathcal{T}}} \times \mathcal{NN}^o_{{\mathcal{T}}}$
is given by
${\mathcal{M}} \,:\!=\, \mathcal{NN}^u_{{\mathcal{T}}} \times \mathcal{NN}^o_{{\mathcal{T}}}$
is given by
 \begin{equation} \Xi _{\beta }(\mathcal{T}, \theta _{\Phi }) = \mathop{argmin}\limits_{\underline {\psi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\psi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi }), \end{equation}
\begin{equation} \Xi _{\beta }(\mathcal{T}, \theta _{\Phi }) = \mathop{argmin}\limits_{\underline {\psi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\psi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} F_{\mathcal{T},\beta }(\underline {\psi },\overline {\psi }), \end{equation}
In summary, the problem function
 $\Xi _{\beta }$
maps a training set
$\Xi _{\beta }$
maps a training set
 $\mathcal{T}$
, and the weights
$\mathcal{T}$
, and the weights
 $\theta _{\Phi }$
of a corresponding pre-trained neural network
$\theta _{\Phi }$
of a corresponding pre-trained neural network
 $\Phi$
, to the set of interval neural networks
$\Phi$
, to the set of interval neural networks
 $\{(\underline {\psi },\overline {\psi })\} \subseteq {\mathcal{N} \mathcal{N}}_{\Phi }^u \times {\mathcal{N} \mathcal{N}}_{\Phi }^o$
, which attain the minimum value of
$\{(\underline {\psi },\overline {\psi })\} \subseteq {\mathcal{N} \mathcal{N}}_{\Phi }^u \times {\mathcal{N} \mathcal{N}}_{\Phi }^o$
, which attain the minimum value of
 $F_{\mathcal{T},\beta }$
.
$F_{\mathcal{T},\beta }$
.
Now, in order to measure the approximation error of different algorithms, whose objective is to solve the computational problem defined above, we need to equip
 $\mathcal{M}$
with a suitable distance function. We therefore view
$\mathcal{M}$
with a suitable distance function. We therefore view
 $\mathcal{M}$
as a metric space equipped with the following metric:
$\mathcal{M}$
as a metric space equipped with the following metric:
 \begin{align} d_{\mathcal{M}} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) \,:\!=\, \max \left \{ \sup _{y \in A({\mathcal{U}}_1)} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in A({\mathcal{U}}_1)} \| \underline {\phi }(y) - \underline {\psi }(y) \|_2^2 \right \}, \end{align}
\begin{align} d_{\mathcal{M}} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) \,:\!=\, \max \left \{ \sup _{y \in A({\mathcal{U}}_1)} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in A({\mathcal{U}}_1)} \| \underline {\phi }(y) - \underline {\psi }(y) \|_2^2 \right \}, \end{align}
where we identify the neural networks that are equivalent on
 $A({\mathcal{U}}_1)$
. The observant reader might notice that this metric is slightly different from the distance function introduced in Eq. (4.4). The reason for this is that we wish to have a unified metric for the whole domain
$A({\mathcal{U}}_1)$
. The observant reader might notice that this metric is slightly different from the distance function introduced in Eq. (4.4). The reason for this is that we wish to have a unified metric for the whole domain
 $\Omega$
, and the distance function in Eq. (4.4) is not suitable for this, because it depends on each individual training set. However, we will prove that the computational breakdown for any training set
$\Omega$
, and the distance function in Eq. (4.4) is not suitable for this, because it depends on each individual training set. However, we will prove that the computational breakdown for any training set
 $\mathcal{T}$
happens at a point contained in
$\mathcal{T}$
happens at a point contained in
 $\pi _2({\mathcal{T}})$
.
$\pi _2({\mathcal{T}})$
.
The set of measurements
 $\Lambda$
is the collection of functions that provide us with the information we are allowed to read as an input to an algorithm. We define the measurements for the training sets
$\Lambda$
is the collection of functions that provide us with the information we are allowed to read as an input to an algorithm. We define the measurements for the training sets
 $\mathcal{T}$
and the parameters
$\mathcal{T}$
and the parameters
 $\theta _{\Phi }$
as follows: Given a training set
$\theta _{\Phi }$
as follows: Given a training set
 $\mathcal{T}$
, let
$\mathcal{T}$
, let
 $f_{x,i}^k\,:\, \Omega \to {\mathbb{R}}$
be given by
$f_{x,i}^k\,:\, \Omega \to {\mathbb{R}}$
be given by
 $f_{x,i}^k(({\mathcal{T}}, \theta _{\Phi })) = x^{(k)}_{i}$
, where the index
$f_{x,i}^k(({\mathcal{T}}, \theta _{\Phi })) = x^{(k)}_{i}$
, where the index
 $i$
denotes the
$i$
denotes the
 $i$
’th coordinate of the vector
$i$
’th coordinate of the vector
 $x^{(k)}$
. We define
$x^{(k)}$
. We define
 $f_{y,j}^k \,:\, \Omega \to {\mathbb{R}}$
in the same way to measure the
$f_{y,j}^k \,:\, \Omega \to {\mathbb{R}}$
in the same way to measure the
 $y$
-coordinates of
$y$
-coordinates of
 $\mathcal{T}$
, more precisely
$\mathcal{T}$
, more precisely
 $f^k_{y,j}(({\mathcal{T}}, \theta _{\Phi })) = y^{(k)}_{j}$
. Next, we introduce the measurements of the parameters
$f^k_{y,j}(({\mathcal{T}}, \theta _{\Phi })) = y^{(k)}_{j}$
. Next, we introduce the measurements of the parameters
 $\theta _{\Phi }$
. As we have seen in Eq. (4.1), the parameters
$\theta _{\Phi }$
. As we have seen in Eq. (4.1), the parameters
 $\theta _{\Phi }$
of a neural network
$\theta _{\Phi }$
of a neural network
 $\Phi$
are represented as a finite collection of real numbers
$\Phi$
are represented as a finite collection of real numbers
 $\theta _{\Phi } = \{\theta _{\Phi }^h\}_{h \in H}$
with
$\theta _{\Phi } = \{\theta _{\Phi }^h\}_{h \in H}$
with
 $|H| \lt \infty$
. We then introduce the following measurements: Let
$|H| \lt \infty$
. We then introduce the following measurements: Let
 $f_{\theta }^h \,:\, \Omega \to {\mathbb{R}}$
be given by
$f_{\theta }^h \,:\, \Omega \to {\mathbb{R}}$
be given by
 $f_{\theta }^h(({\mathcal{T}},\theta _{\Phi })) = \theta _{\Phi }^h$
. In summary, our set of measurements is given by
$f_{\theta }^h(({\mathcal{T}},\theta _{\Phi })) = \theta _{\Phi }^h$
. In summary, our set of measurements is given by
 \begin{equation} \Lambda = \{f^k_{y,j},f^k_{x,i},f_{\theta }^h \,:\, \Omega \to {\mathbb{R}} \: | \: i = 1, \ldots , N \;, \; j = 1, \ldots , m, \;, \; k = 1, \ldots , \ell , \; \text{and} \; h \in H\}. \end{equation}
\begin{equation} \Lambda = \{f^k_{y,j},f^k_{x,i},f_{\theta }^h \,:\, \Omega \to {\mathbb{R}} \: | \: i = 1, \ldots , N \;, \; j = 1, \ldots , m, \;, \; k = 1, \ldots , \ell , \; \text{and} \; h \in H\}. \end{equation}
As we have mentioned, in these cases we cannot necessarily access or store the values
 $f_j(\iota )$
on a computer, but we can compute approximations
$f_j(\iota )$
on a computer, but we can compute approximations
 $f_{j,n}(\iota ) \in \mathbb{D} +i \mathbb{D}$
such that
$f_{j,n}(\iota ) \in \mathbb{D} +i \mathbb{D}$
such that
 $f_{j,n}(\iota ) \to f_{j}(\iota )$
as
$f_{j,n}(\iota ) \to f_{j}(\iota )$
as
 $n\to \infty$
. The concept of
$n\to \infty$
. The concept of
 $\Delta _1$
-information formalises this.
$\Delta _1$
-information formalises this.
Definition 6.2 (
 $\Delta _{1}$
-information [Reference Bastounis, Hansen and Vlačić11]). Let
$\Delta _{1}$
-information [Reference Bastounis, Hansen and Vlačić11]). Let
 $\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
be a computational problem. We say that
$\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
be a computational problem. We say that
 $\Lambda$
has
$\Lambda$
has
 $\Delta _{1}$
-information if for each
$\Delta _{1}$
-information if for each
 $f_j \in \Lambda$
there are mappings
$f_j \in \Lambda$
there are mappings
 $f_{j,n}\,:\, \Omega \rightarrow \mathbb{Q} + i \mathbb{Q}$
such that
$f_{j,n}\,:\, \Omega \rightarrow \mathbb{Q} + i \mathbb{Q}$
such that
 $|f_{j,n}(\iota )-f_j(\iota )|\leq 2^{-n}$
for all
$|f_{j,n}(\iota )-f_j(\iota )|\leq 2^{-n}$
for all
 $\iota \in \Omega$
. Furthermore, if
$\iota \in \Omega$
. Furthermore, if
 $\widehat \Lambda$
is a collection of such functions, such that
$\widehat \Lambda$
is a collection of such functions, such that
 $\Lambda$
has
$\Lambda$
has
 $\Delta _1$
-information, we say that
$\Delta _1$
-information, we say that
 $\widehat \Lambda$
provides
$\widehat \Lambda$
provides
 $\Delta _1$
-information for
$\Delta _1$
-information for
 $\Lambda$
and we denote the family of all such
$\Lambda$
and we denote the family of all such
 $\widehat \Lambda$
by
$\widehat \Lambda$
by
 $\mathcal{L}^1(\Lambda )$
.
$\mathcal{L}^1(\Lambda )$
.
In the above definition, the set
 $\widehat \Lambda$
corresponds to one particular choice of
$\widehat \Lambda$
corresponds to one particular choice of
 $\Delta _1$
-information. However, we want to have algorithms that can handle any choice of such information. To formalise this, we define computational problems with
$\Delta _1$
-information. However, we want to have algorithms that can handle any choice of such information. To formalise this, we define computational problems with
 $\Delta _1$
-information.
$\Delta _1$
-information.
Definition 6.3 (Computational problem with
 $\Delta _1$
-information [Reference Bastounis, Hansen and Vlačić11]). Let
$\Delta _1$
-information [Reference Bastounis, Hansen and Vlačić11]). Let
 $J$
be an index set for
$J$
be an index set for
 $\Lambda$
. Then a computational problem where
$\Lambda$
. Then a computational problem where
 $\Lambda$
has
$\Lambda$
has
 $\Delta _1$
-information is denoted by
$\Delta _1$
-information is denoted by
 $ \{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1} \,:\!=\, \{\widetilde \Xi ,\widetilde \Omega ,\mathcal{M},\widetilde \Lambda \},$
where
$ \{\Xi ,\Omega ,\mathcal{M},\Lambda \}^{\Delta _1} \,:\!=\, \{\widetilde \Xi ,\widetilde \Omega ,\mathcal{M},\widetilde \Lambda \},$
where
 \begin{equation*} \widetilde \Omega = \left \{ \widetilde \iota = \{f_{j,n}(\iota )\}_{j, n\in J \times \mathbb{N}} \, : \, \iota \in \Omega , \{f_j\}_{j \in J} = \Lambda , |f_{j,n}(\iota )-f_j(\iota )|\leq 2^{-n}\right \}, \end{equation*}
\begin{equation*} \widetilde \Omega = \left \{ \widetilde \iota = \{f_{j,n}(\iota )\}_{j, n\in J \times \mathbb{N}} \, : \, \iota \in \Omega , \{f_j\}_{j \in J} = \Lambda , |f_{j,n}(\iota )-f_j(\iota )|\leq 2^{-n}\right \}, \end{equation*}
Moreover, if
 $\widetilde \iota = \{f_{j,n}(\iota )\}_{j, n\in J \times \mathbb{N}}\in \widetilde \Omega$
then we define
$\widetilde \iota = \{f_{j,n}(\iota )\}_{j, n\in J \times \mathbb{N}}\in \widetilde \Omega$
then we define
 $\widetilde \Xi (\widetilde \iota ) = \Xi (\iota )$
and
$\widetilde \Xi (\widetilde \iota ) = \Xi (\iota )$
and
 $\widetilde f_{j,n}(\widetilde \iota ) = f_{j,n}(\iota )$
. We also set
$\widetilde f_{j,n}(\widetilde \iota ) = f_{j,n}(\iota )$
. We also set
 $\widetilde \Lambda = \{\widetilde f_{j,n}\}_{j,n \in J \times \mathbb{N}}$
. Note that
$\widetilde \Lambda = \{\widetilde f_{j,n}\}_{j,n \in J \times \mathbb{N}}$
. Note that
 $\widetilde \Xi$
is well defined by Definition 6.1 of a computational problem and that the definition of
$\widetilde \Xi$
is well defined by Definition 6.1 of a computational problem and that the definition of
 $\widetilde \Omega$
includes all possible instances of
$\widetilde \Omega$
includes all possible instances of
 $\Delta _1$
-information
$\Delta _1$
-information
 $\widehat \Lambda \in \mathcal{L}^1(\Lambda )$
.
$\widehat \Lambda \in \mathcal{L}^1(\Lambda )$
.
Lastly, we describe the precise notation for inexact representations of the elements in our specific case. Let
 $\hat \Lambda = \{ f_{n} \: | \: f \in \Lambda , \: n \in \mathbb{N} \}$
be a set that provides
$\hat \Lambda = \{ f_{n} \: | \: f \in \Lambda , \: n \in \mathbb{N} \}$
be a set that provides
 $\Delta _1$
-information for
$\Delta _1$
-information for
 $\Omega$
as defined in Definition 6.2. Then, for an arbitrary
$\Omega$
as defined in Definition 6.2. Then, for an arbitrary
 $({\mathcal{T}},\theta _{\Phi }) \in \Omega$
and
$({\mathcal{T}},\theta _{\Phi }) \in \Omega$
and
 $k \in \{1, \ldots , \ell \}$
, the corresponding inexact representation of
$k \in \{1, \ldots , \ell \}$
, the corresponding inexact representation of
 $(x^{(k)},y^{(k)}) \in {\mathcal{T}}$
is the pair of sequences
$(x^{(k)},y^{(k)}) \in {\mathcal{T}}$
is the pair of sequences
 $(\tilde x^{(k)},\tilde y^{(k)})$
, where
$(\tilde x^{(k)},\tilde y^{(k)})$
, where
 \begin{align} \tilde x^{(k)} = \big\{\big\{f_{x,i,n}^k({\mathcal{T}},\theta _{\Phi })\big\}_{i =1}^{i = N}\big\}_{n \in \mathbb{N}} \quad \text{and} \quad \tilde y^{(k)} = \big\{ \big\{ f_{y,j,n}^k({\mathcal{T}}, \theta _{\Phi })\big\}_{j = 1}^{j = m}\big\}_{n \in \mathbb{N}}. \end{align}
\begin{align} \tilde x^{(k)} = \big\{\big\{f_{x,i,n}^k({\mathcal{T}},\theta _{\Phi })\big\}_{i =1}^{i = N}\big\}_{n \in \mathbb{N}} \quad \text{and} \quad \tilde y^{(k)} = \big\{ \big\{ f_{y,j,n}^k({\mathcal{T}}, \theta _{\Phi })\big\}_{j = 1}^{j = m}\big\}_{n \in \mathbb{N}}. \end{align}
Similarly, for the parameters
 $\theta _{\Phi } = \{\theta _{\Phi }^h\}_{h \in H}$
. The inexact representation
$\theta _{\Phi } = \{\theta _{\Phi }^h\}_{h \in H}$
. The inexact representation
 $\tilde {\theta }_{\Phi }^h$
of
$\tilde {\theta }_{\Phi }^h$
of
 $\theta _{\Phi }^h$
is the sequence
$\theta _{\Phi }^h$
is the sequence
 \begin{align*} \tilde {\theta }_{\Phi }^h = \big\{ f_{\theta ,n}^h({\mathcal{T}},\theta _{\Phi })\big\}_{n \in \mathbb{N}}, \quad \text{for each $h \in H$.} \end{align*}
\begin{align*} \tilde {\theta }_{\Phi }^h = \big\{ f_{\theta ,n}^h({\mathcal{T}},\theta _{\Phi })\big\}_{n \in \mathbb{N}}, \quad \text{for each $h \in H$.} \end{align*}
We also recall that the approximations satisfy the same well-posednes assumptions as
 $\mathcal{T}$
and
$\mathcal{T}$
and
 $\Phi$
. More precisely, that
$\Phi$
. More precisely, that
 ${\mathcal{T}}_n \in T_{\ell ,{\mathcal{U}}_1}$
for each
${\mathcal{T}}_n \in T_{\ell ,{\mathcal{U}}_1}$
for each
 $n \in \mathbb{N}$
, and that the neural network
$n \in \mathbb{N}$
, and that the neural network
 $\Phi _n$
, represented by the parameters
$\Phi _n$
, represented by the parameters
 $\{\theta _{\Phi }^{h,n}\}_{h \in H}$
, satisfies
$\{\theta _{\Phi }^{h,n}\}_{h \in H}$
, satisfies
 $\Phi _n \in \mathcal{W}({\mathcal{T}}_n, {\mathcal{N} \mathcal{N}}_{\ell })$
for each
$\Phi _n \in \mathcal{W}({\mathcal{T}}_n, {\mathcal{N} \mathcal{N}}_{\ell })$
for each
 $n \in \mathbb{N}$
. We do this to show that computational barriers arise, even when the approximations are well posed.
$n \in \mathbb{N}$
. We do this to show that computational barriers arise, even when the approximations are well posed.
6.2. Algorithmic preliminaries: a user-friendly guide
The main goal in this section is to introduce the concepts of a general algorithm, and of breakdown epsilons, which are needed for the formal statement and proof of Theorem 4.2. We follow the lines of [Reference Bastounis, Hansen and Vlačić11] in our presentation of these concepts also.
6.2.1. General algorithms
The most common theoretical definition of an algorithm is a Turing machine; however, in this paper, we use a more general definition of an algorithm, as this makes our impossibility statements stronger. In particular, by using a definition which encompasses any model of computation (such as Turing machines or real BSS machines), we ensure that proved lower bounds for computations are universally true for all reasonable models of computation. In the SCI hierarchy, this definition is given in terms of a general algorithm (defined below), whose goal is to capture the notion of a deterministic algorithm for a given computational problem.
Definition 6.4 (General Algorithm [Reference Bastounis, Hansen and Vlačić11]). Given a computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, a general algorithm is a mapping
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, a general algorithm is a mapping
 $\Gamma \,:\,\Omega \to \mathcal{M}\cup \{ \mathrm{NH} \}$
, where the metric space
$\Gamma \,:\,\Omega \to \mathcal{M}\cup \{ \mathrm{NH} \}$
, where the metric space
 $\mathcal{M}\cup \{ \mathrm{NH} \}$
is as defined in Eq. (6.6), such that for each
$\mathcal{M}\cup \{ \mathrm{NH} \}$
is as defined in Eq. (6.6), such that for each
 $\iota \in \Omega$
the following hold
$\iota \in \Omega$
the following hold
-
(i) There exists a non-empty subset of evaluations
$\Lambda _\Gamma (\iota ) \subset \Lambda$
, and whenever
$\Gamma (\iota ) \neq \mathrm{NH}$
, then
$\Lambda _{\Gamma }(\iota )$
is finite. -
(ii) The action of
$\,\Gamma$
on
$\iota$
is determined uniquely by
$\{f(\iota )\}_{f \in \Lambda _\Gamma (\iota )}$
, -
(ii) For every
$\iota ' \in \Omega$
such that
$f(\iota ')=f(\iota )$
for every
$f\in \Lambda _\Gamma (\iota )$
, it holds that
$\Lambda _\Gamma (\iota ')=\Lambda _\Gamma (\iota )$
.










This definition requires some comments. The object
 $\mathrm{NH}$
stands for ‘non-haltin’ and is meant to capture the event that an algorithm runs forever. The introduction of this object requires that we extend the metric
$\mathrm{NH}$
stands for ‘non-haltin’ and is meant to capture the event that an algorithm runs forever. The introduction of this object requires that we extend the metric
 $d_{{\mathcal{M}}}$
on
$d_{{\mathcal{M}}}$
on
 $\mathcal{M}$
to also handle
$\mathcal{M}$
to also handle
 $\mathrm{NH}$
. We do this as follows
$\mathrm{NH}$
. We do this as follows
 \begin{equation} d_{{\mathcal{M}}}(x,y) = \begin{cases} d_{{\mathcal{M}}}(x,y) &\text{if } x,y \in \mathcal{M}, \\ 0 &\text{if } x=y=\mathrm{NH,} \\ \infty &\text{otherwise.} \end{cases} \end{equation}
\begin{equation} d_{{\mathcal{M}}}(x,y) = \begin{cases} d_{{\mathcal{M}}}(x,y) &\text{if } x,y \in \mathcal{M}, \\ 0 &\text{if } x=y=\mathrm{NH,} \\ \infty &\text{otherwise.} \end{cases} \end{equation}
The three other properties listed in the above definition are requirements that any reasonable definition of an algorithm must satisfy. The first says that if the algorithm does halt, then it can only have read a finite amount of information. The second condition says that the algorithm can only depend on the information it has read. In particular, it cannot depend on information about
 $\iota$
that it has not read. The third condition ensures consistency. It says that if the algorithm reads the same information about two different inputs, then it cannot behave differently for these two inputs.
$\iota$
that it has not read. The third condition ensures consistency. It says that if the algorithm reads the same information about two different inputs, then it cannot behave differently for these two inputs.
Remark 6.5 (The purpose of a general algorithm: universal impossibility results). The purpose of a general algorithm is to have a definition that encompasses any model of computation, and that allows impossibility results to become universal. Given that there are several non-equivalent models of computation, impossibility results are shown with this general definition of an algorithm.
Randomness is an indispensable tool in computational mathematics which is used in many different areas, including optimisation, algebraic computation, network routing, learning and data science. This motivates the need for formalising what we mean by a randomised algorithm. According to [Reference Bastounis, Hansen and Vlačić11], we define a randomised general algorithm as follows.
Definition 6.6 (Randomised General Algorithm [Reference Bastounis, Hansen and Vlačić11]). Given a computational problem
 $\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, where
$\{\Xi ,\Omega ,\mathcal{M},\Lambda \}$
, where
 $\Lambda = \{f_k \, \vert \, k \in \mathbb{N}, \, k\leq |\Lambda | \}$
, a randomised general algorithm (RGA) is a collection
$\Lambda = \{f_k \, \vert \, k \in \mathbb{N}, \, k\leq |\Lambda | \}$
, a randomised general algorithm (RGA) is a collection
 $X$
of general algorithms
$X$
of general algorithms
 $\Gamma \,:\,\Omega \to \mathcal{M}\cup \{\text{NH}\}$
, a sigma-algebra
$\Gamma \,:\,\Omega \to \mathcal{M}\cup \{\text{NH}\}$
, a sigma-algebra
 $\mathcal{F}$
on
$\mathcal{F}$
on
 $X$
, and a family of probability measures
$X$
, and a family of probability measures
 $\{\mathbb{P}_{\iota }\}_{\iota \in \Omega }$
on
$\{\mathbb{P}_{\iota }\}_{\iota \in \Omega }$
on
 $\mathcal{F}$
such that the following conditions hold:
$\mathcal{F}$
such that the following conditions hold:
-
(i) For each
$\iota \in \Omega$
, the mapping
$\Gamma ^{\mathrm{ran}}_{\iota }\,:\,(X,\mathcal{F}) \to (\mathcal{M}\cup \{\text{NH}\}, \mathcal{B})$
, defined by
$\Gamma ^{\mathrm{ran}}_{\iota }(\Gamma ) = \Gamma (\iota )$
, is a random variable, where
$\mathcal{B}$
is the Borel sigma-algebra on
$\mathcal{M}\cup \{\text{NH}\}$
. -
(ii) For each
$n \in \mathbb{N}$
and
$\iota \in \Omega$
, we have
$\lbrace \Gamma \in X \, \vert \, T_{\Gamma }(\iota ) \leq n \rbrace \in \mathcal{F}$
, where is the minimum amount of input information.
\begin{align*} T_{\Gamma }(\iota ) \,:\!=\, \sup \{ m \in \mathbb{N} \: | \: f_m \in \Lambda _{\Gamma }(\iota ) \} \end{align*}
-
(iii) For all
$\iota _1,\iota _2 \in \Omega$
and
$E \in \mathcal{F}$
so that, for every
$\Gamma \in E$
and every
$f \in \Lambda _{\Gamma }(\iota _1)$
, we have
$f(\iota _1) = f(\iota _2)$
, it holds that
$\mathbb{P}_{\iota _1}(E) = \mathbb{P}_{\iota _2}(E)$
.















Here, the first two conditions are measure-theoretic and ensure that one can use standard tools from probability theory to prove results about randomised general algorithms. The final condition ensures that the algorithm acts consistently on the inputs. In particular, for identical evaluations, the probabilistic laws do not change. It was established in [Reference Bastounis, Hansen and Vlačić11] that condition (ii), for a given RGA
 $(X,\mathcal{F},\{{\mathbb{P}}_\iota \}_{\iota \in \Omega })$
, holds independently of the choice of the enumeration of
$(X,\mathcal{F},\{{\mathbb{P}}_\iota \}_{\iota \in \Omega })$
, holds independently of the choice of the enumeration of
 $\Lambda$
.
$\Lambda$
.
Remark 6.7. Following [Reference Bastounis, Hansen and Vlačić11], we abuse notation slightly, and also write RGA for the family of all randomised general algorithms
 $(X,\mathcal{F}, \{\mathbb{P}_{\iota }\}_{\iota \in \Omega })$
, and refer to the algorithms in RGA by
$(X,\mathcal{F}, \{\mathbb{P}_{\iota }\}_{\iota \in \Omega })$
, and refer to the algorithms in RGA by
 $\Gamma ^{\mathrm{ran}}$
.
$\Gamma ^{\mathrm{ran}}$
.
Finally, we end this section with a formalised version of our main theorem.
Theorem 6.8. Let
 $m,N \in \mathbb{N}$
with
$m,N \in \mathbb{N}$
with
 $N \geq 2$
, and let
$N \geq 2$
, and let
 $A \in {\mathbb{R}}^{m\times N}$
be such that
$A \in {\mathbb{R}}^{m\times N}$
be such that
 $1\leq \mathrm{rank}(A) \lt N$
. Let
$1\leq \mathrm{rank}(A) \lt N$
. Let
 $\ell \geq 2$
,
$\ell \geq 2$
,
 $\kappa \in (0,1/8)$
and let
$\kappa \in (0,1/8)$
and let
 ${\mathcal{N} \mathcal{N}}_{\ell }$
be a class of neural networks that satisfies Assumption 2.1
. Then for any
${\mathcal{N} \mathcal{N}}_{\ell }$
be a class of neural networks that satisfies Assumption 2.1
. Then for any
 $\beta \in (0, \sqrt {\kappa }/(4\sqrt {2N}))$
, there exist infinitely many model classes
$\beta \in (0, \sqrt {\kappa }/(4\sqrt {2N}))$
, there exist infinitely many model classes
 ${\mathcal{U}}_1 \subseteq B_1^N(0)$
, and for each model class, infinitely many computational problems
${\mathcal{U}}_1 \subseteq B_1^N(0)$
, and for each model class, infinitely many computational problems
 $\{\Xi _{\beta },\Omega ,\mathcal{M},\Lambda \}$
, where the objects are as described in Equations (4.2) and (6.2) to (6.4), such that there exists a set
$\{\Xi _{\beta },\Omega ,\mathcal{M},\Lambda \}$
, where the objects are as described in Equations (4.2) and (6.2) to (6.4), such that there exists a set
 $\hat {\Lambda } \in \mathcal{L}^1(\Lambda )$
, giving
$\hat {\Lambda } \in \mathcal{L}^1(\Lambda )$
, giving
 $\Delta _1$
-information, such that for the corresponding computational problem
$\Delta _1$
-information, such that for the corresponding computational problem
 $\{\Xi _{\beta },\Omega ,\mathcal{M},\hat \Lambda \}$
, we have that there exists no algorithm, not even randomised (with probability
$\{\Xi _{\beta },\Omega ,\mathcal{M},\hat \Lambda \}$
, we have that there exists no algorithm, not even randomised (with probability
 $p \geq 1/2$
), that approximates an optimal pair of interval neural networks
$p \geq 1/2$
), that approximates an optimal pair of interval neural networks
 $(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }({\mathcal{T}}, \theta _{\Phi })$
, in the sense of Eq. (4.4), for all elements
$(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }({\mathcal{T}}, \theta _{\Phi })$
, in the sense of Eq. (4.4), for all elements
 $({\mathcal{T}},\theta _{\Phi }) \in \Omega$
to accuracy
$({\mathcal{T}},\theta _{\Phi }) \in \Omega$
to accuracy
 $\kappa /2$
.
$\kappa /2$
.
7. Proof of the main result
7.1. A few preliminary results for the proof of theorem 6.8
Lemma 7.1. Let
 $A \in {\mathbb{R}}^{m\times N}$
with
$A \in {\mathbb{R}}^{m\times N}$
with
 $1 \leq \mathrm{rank}(A) \lt N$
. Furthermore, let
$1 \leq \mathrm{rank}(A) \lt N$
. Furthermore, let
 $\kappa , \beta \gt 0$
,
$\kappa , \beta \gt 0$
,
 $\ell \geq 2$
,
$\ell \geq 2$
,
 $\mathcal{U}_1 \subset {\mathbb{R}}^N$
, and let
$\mathcal{U}_1 \subset {\mathbb{R}}^N$
, and let
 ${\mathcal{N} \mathcal{N}}_{\ell }$
be a class of neural networks that satisfies Assumption 2.1
. Assume that there exists two elements
${\mathcal{N} \mathcal{N}}_{\ell }$
be a class of neural networks that satisfies Assumption 2.1
. Assume that there exists two elements
 $x^{(1)}, x^{(2)} \in \mathcal{U}_1$
, such that
$x^{(1)}, x^{(2)} \in \mathcal{U}_1$
, such that
 $Ax^{(1)} = Ax^{(2)}$
and such that
$Ax^{(1)} = Ax^{(2)}$
and such that
 $\|x^{(1)} - x^{(2)}\|_{2}^{2} = \kappa$
. Moreover, let
$\|x^{(1)} - x^{(2)}\|_{2}^{2} = \kappa$
. Moreover, let
 $\mathcal{T}_0 = \{(x^{(1)}, Ax^{(1)}), (x^{(2)}, Ax^{(2)})\}$
and let
$\mathcal{T}_0 = \{(x^{(1)}, Ax^{(1)}), (x^{(2)}, Ax^{(2)})\}$
and let
 $\mathcal{T}_1 \in T_{\ell -2, \mathcal{U}_1}$
be any training set where each of the second coordinates are distinct and not equal to
$\mathcal{T}_1 \in T_{\ell -2, \mathcal{U}_1}$
be any training set where each of the second coordinates are distinct and not equal to
 $Ax^{(1)}$
. With
$Ax^{(1)}$
. With
 ${\mathcal{T}} = {\mathcal{T}}_0 \cup {\mathcal{T}}_1$
, let
${\mathcal{T}} = {\mathcal{T}}_0 \cup {\mathcal{T}}_1$
, let
 $\Phi \in \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
, where
$\Phi \in \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
, where
 $\mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
is as defined in Eq. (2.8), and let
$\mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
is as defined in Eq. (2.8), and let
 ${\mathcal{N} \mathcal{N}}_{\Phi }^u$
and
${\mathcal{N} \mathcal{N}}_{\Phi }^u$
and
 ${\mathcal{N} \mathcal{N}}_{\Phi }^o$
be the optimisation classes defined in Eq. (2.9). Then
${\mathcal{N} \mathcal{N}}_{\Phi }^o$
be the optimisation classes defined in Eq. (2.9). Then
 \begin{equation} \min _{\underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} F_{\mathcal{T}_0 \cup \mathcal{T}_{1}, \beta } (\underline {\phi },\overline {\phi }) = \min _{\underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} F_{\mathcal{T}_0, \beta } (\underline {\phi },\overline {\phi }) \leq 2\beta \sqrt {N\kappa }. \end{equation}
\begin{equation} \min _{\underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} F_{\mathcal{T}_0 \cup \mathcal{T}_{1}, \beta } (\underline {\phi },\overline {\phi }) = \min _{\underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} F_{\mathcal{T}_0, \beta } (\underline {\phi },\overline {\phi }) \leq 2\beta \sqrt {N\kappa }. \end{equation}
Proof. We start by arguing for the first equality in (7.1). Since all the second coordinates in
 $\mathcal{T}_1$
are distinct, we must have that the pre-trained neural network
$\mathcal{T}_1$
are distinct, we must have that the pre-trained neural network
 $\Phi \in \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
interpolates all the points in
$\Phi \in \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
interpolates all the points in
 ${\mathcal{T}}_1$
, this is because
${\mathcal{T}}_1$
, this is because
 $\Phi \in \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
implies that the neural network
$\Phi \in \mathcal{W}({\mathcal{T}},{\mathcal{N} \mathcal{N}}_{\ell })$
implies that the neural network
 $\Phi$
has an excellent performance on all elements in
$\Phi$
has an excellent performance on all elements in
 $\pi _2({\mathcal{T}})$
, which means that
$\pi _2({\mathcal{T}})$
, which means that
 $\Phi$
maps
$\Phi$
maps
 $y = Ax$
to the unique
$y = Ax$
to the unique
 $x$
in the case where the elements in
$x$
in the case where the elements in
 $\pi _2(\mathcal{T}_1)$
are distinct. Thus, by part (b) in Assumption 2.1, we get that there exists
$\pi _2(\mathcal{T}_1)$
are distinct. Thus, by part (b) in Assumption 2.1, we get that there exists
 $\underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u$
and
$\underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u$
and
 $\overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o$
that for each
$\overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o$
that for each
 $(x,y) \in \mathcal{T}_1$
, maps
$(x,y) \in \mathcal{T}_1$
, maps
 $y\mapsto x$
, this yields that the objective function
$y\mapsto x$
, this yields that the objective function
 $F_{\mathcal{T}_1,\beta }$
is zero on the set
$F_{\mathcal{T}_1,\beta }$
is zero on the set
 $\mathcal{T}_1$
. Clearly, we can choose neural networks with this property on the extended training set
$\mathcal{T}_1$
. Clearly, we can choose neural networks with this property on the extended training set
 $\mathcal{T}_0\cup \mathcal{T}_1$
without affecting the optimal value of
$\mathcal{T}_0\cup \mathcal{T}_1$
without affecting the optimal value of
 $F_{\mathcal{T}_0\cup \mathcal{T}_1, \beta }$
, since we are minimising over a class of networks which is
$F_{\mathcal{T}_0\cup \mathcal{T}_1, \beta }$
, since we are minimising over a class of networks which is
 $\ell$
-interpolatory. This means that the optimal neural networks interpolate all the data in
$\ell$
-interpolatory. This means that the optimal neural networks interpolate all the data in
 $\mathcal{T}_1$
resulting in the first equality.
$\mathcal{T}_1$
resulting in the first equality.
To prove the inequality in (7.1), let
 $y=Ax^{(1)}=Ax^{(2)}$
and let
$y=Ax^{(1)}=Ax^{(2)}$
and let
 $(\underline {\psi },\overline {\psi }) \in {\mathcal{N} \mathcal{N}}_{\Phi }^u \times {\mathcal{N} \mathcal{N}}_{\Phi }^o$
be such that
$(\underline {\psi },\overline {\psi }) \in {\mathcal{N} \mathcal{N}}_{\Phi }^u \times {\mathcal{N} \mathcal{N}}_{\Phi }^o$
be such that
 $\overline {\psi }(y) = \max \{x^{(1)}, x^{(2)}\}$
and
$\overline {\psi }(y) = \max \{x^{(1)}, x^{(2)}\}$
and
 $\underline {\psi }(y) = \min \{x^{(1)}, x^{(2)}\}$
. We then have that
$\underline {\psi }(y) = \min \{x^{(1)}, x^{(2)}\}$
. We then have that
 \begin{align*} \min _{\underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} &F_{\mathcal{T}_0, \beta } (\underline {\phi },\overline {\phi }) \leq F_{\mathcal{T}_0, \beta } (\underline {\psi },\overline {\psi }) = 2\beta \|\max \{x^{(1)}, x^{(2)}\} - \min \{x^{(1)}, x^{(2)}\}\|_1 \\ &= 2\beta \sum _{i = 1}^N |x^{(1)}_i - x^{(2)}_i| = 2\beta \|x^{(1)} - x^{(2)}\|_{1} \leq 2\beta \sqrt {N} \|x^{(1)} - x^{(2)}\|_2 = 2\beta \sqrt {N\kappa }, \end{align*}
\begin{align*} \min _{\underline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^u, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\Phi }^o} &F_{\mathcal{T}_0, \beta } (\underline {\phi },\overline {\phi }) \leq F_{\mathcal{T}_0, \beta } (\underline {\psi },\overline {\psi }) = 2\beta \|\max \{x^{(1)}, x^{(2)}\} - \min \{x^{(1)}, x^{(2)}\}\|_1 \\ &= 2\beta \sum _{i = 1}^N |x^{(1)}_i - x^{(2)}_i| = 2\beta \|x^{(1)} - x^{(2)}\|_{1} \leq 2\beta \sqrt {N} \|x^{(1)} - x^{(2)}\|_2 = 2\beta \sqrt {N\kappa }, \end{align*}
where we in the last equality used the assumption that
 $\|x^{(1)} - x^{(2)}\|_{2} = \sqrt {\kappa }$
.
$\|x^{(1)} - x^{(2)}\|_{2} = \sqrt {\kappa }$
.
Lemma 7.2. Let
 $\kappa \gt 0$
and
$\kappa \gt 0$
and
 $c \in (0,1]$
, and let
$c \in (0,1]$
, and let
 $a,b^1,b^2 \in {\mathbb{R}}^n$
be such that
$a,b^1,b^2 \in {\mathbb{R}}^n$
be such that
-
(i)
$\|b^i\|_2^2 \leq c \kappa /2$
for
$i = 1,2$
, -
(ii)
$\|a\|_2^2 = 2 \kappa$
.



Then
 \begin{equation} \|\max \{a + b^1,0\} \|_2^2 + \|\max \{ -a + b^2,0\}\|_2^2 \geq \big(2 + c -\sqrt {8c}\big)\kappa . \end{equation}
\begin{equation} \|\max \{a + b^1,0\} \|_2^2 + \|\max \{ -a + b^2,0\}\|_2^2 \geq \big(2 + c -\sqrt {8c}\big)\kappa . \end{equation}
Proof. We start by splitting the vector
 $a$
into its positive and negative parts
$a$
into its positive and negative parts
 $a^+$
and
$a^+$
and
 $a^-$
, where
$a^-$
, where
 $a^+ \,:\!=\, \max \{a,0\}$
, and
$a^+ \,:\!=\, \max \{a,0\}$
, and
 $a^{-} \,:\!=\, \max \{-a,0\}$
. We note that
$a^{-} \,:\!=\, \max \{-a,0\}$
. We note that
 $a = a^+ - a^{-}$
and that the entries of
$a = a^+ - a^{-}$
and that the entries of
 $a^{-}$
are non-negative. Furthermore, since the two vectors
$a^{-}$
are non-negative. Furthermore, since the two vectors
 $a^+$
and
$a^+$
and
 $a^{-}$
have disjoint support, we have that
$a^{-}$
have disjoint support, we have that
 $\|a^+\|_2^2 + \|a^-\|_2^2 = \|a\|_2^2 = 2 \kappa$
from condition (ii). To ease the notation in what follows, we let
$\|a^+\|_2^2 + \|a^-\|_2^2 = \|a\|_2^2 = 2 \kappa$
from condition (ii). To ease the notation in what follows, we let
 $S^+ = supp (a^+) \subset \{1,\ldots ,N\}$
denote the denote support set of
$S^+ = supp (a^+) \subset \{1,\ldots ,N\}$
denote the denote support set of
 $a^+$
, and we let
$a^+$
, and we let
 $S^+_{c} = \{1,\ldots ,N\}\setminus S^+$
denote its complement. Furthermore, for an index set
$S^+_{c} = \{1,\ldots ,N\}\setminus S^+$
denote its complement. Furthermore, for an index set
 $S \subset \{1,\ldots , N\}$
and a vector
$S \subset \{1,\ldots , N\}$
and a vector
 $x \in {\mathbb{R}}^N$
, we let
$x \in {\mathbb{R}}^N$
, we let
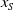 $x_{S}$
be the vector with entries
$x_{S}$
be the vector with entries
 $(x_{S})_{i} = x_i$
if
$(x_{S})_{i} = x_i$
if
 $i \in S$
and zero otherwise.
$i \in S$
and zero otherwise.
Consider the following two optimisation problems,
 \begin{align} &\min _{b \in {\mathbb{R}}^n} \| \max \{a + b, 0\}\|_2^2 \quad \text{subject to} \quad \|b\|_2^2 \leq \!\frac {c \kappa }{2}, \\[-28pt] \nonumber \end{align}
\begin{align} &\min _{b \in {\mathbb{R}}^n} \| \max \{a + b, 0\}\|_2^2 \quad \text{subject to} \quad \|b\|_2^2 \leq \!\frac {c \kappa }{2}, \\[-28pt] \nonumber \end{align}
 \begin{align} & \min _{b \in {\mathbb{R}}^n} \| \max \{-a + b, 0\}\|_2^2 \quad \text{subject to} \quad \|b\|_2^2 \leq \! \frac {c \kappa }{2}. \end{align}
\begin{align} & \min _{b \in {\mathbb{R}}^n} \| \max \{-a + b, 0\}\|_2^2 \quad \text{subject to} \quad \|b\|_2^2 \leq \! \frac {c \kappa }{2}. \end{align}
In what follows, we find a lower bound for the optimal value of each of these optimisation problems. Once we have these bounds, we can use these to compute the lower bound in (7.2).
We start by considering (Q 1
) and consider the two cases
 $\|a^+\|_{2}^{2} \leq c\kappa /2$
and
$\|a^+\|_{2}^{2} \leq c\kappa /2$
and
 $\|a^+\|_{2}^{2} \gt c\kappa /2$
separately. If
$\|a^+\|_{2}^{2} \gt c\kappa /2$
separately. If
 $\|a^+\|_{2}^{2} \leq c\kappa /2$
, it is easy to see that
$\|a^+\|_{2}^{2} \leq c\kappa /2$
, it is easy to see that
 $b=-a^+$
is a feasible point for (Q 1
) and that
$b=-a^+$
is a feasible point for (Q 1
) and that
 $b=-a^+$
attains the minimum value
$b=-a^+$
attains the minimum value
 $0$
. On the other hand, if
$0$
. On the other hand, if
 $\|a^+\|_{2}^{2} \gt c\kappa /2$
and
$\|a^+\|_{2}^{2} \gt c\kappa /2$
and
 $b\in {\mathbb{R}}^N$
satisfies
$b\in {\mathbb{R}}^N$
satisfies
 $\|b\|_{2}^{2} \leq c\kappa /2$
, we have that
$\|b\|_{2}^{2} \leq c\kappa /2$
, we have that
 \begin{align*} \|\max \{a+ b,0\}\|_2^2 &=\|\max \{a^+ + b_{S^+} + b_{S^{+}_{c}}- a^-,0\}\|_2^2 \geq \|\max \{a^+ + b_{S^+},0\}\|_2^2 \\ &\geq \left \|a^+ - \sqrt {\tfrac {c\kappa }{2}}\tfrac {1}{\|a^+\|_{2}}a^+\right \|_{2}^{2} = \left ( 1 - \sqrt {\tfrac {c\kappa }{2}} \tfrac {1}{\|a^+\|_{2}} \right )^2\|a^+\|_{2}^{2} \\ &=\frac {c\kappa }{2} + \|a^+\|_{2}\left(\|a^+\|_{2} - \sqrt {2c\kappa }\right) \gt 0. \end{align*}
\begin{align*} \|\max \{a+ b,0\}\|_2^2 &=\|\max \{a^+ + b_{S^+} + b_{S^{+}_{c}}- a^-,0\}\|_2^2 \geq \|\max \{a^+ + b_{S^+},0\}\|_2^2 \\ &\geq \left \|a^+ - \sqrt {\tfrac {c\kappa }{2}}\tfrac {1}{\|a^+\|_{2}}a^+\right \|_{2}^{2} = \left ( 1 - \sqrt {\tfrac {c\kappa }{2}} \tfrac {1}{\|a^+\|_{2}} \right )^2\|a^+\|_{2}^{2} \\ &=\frac {c\kappa }{2} + \|a^+\|_{2}\left(\|a^+\|_{2} - \sqrt {2c\kappa }\right) \gt 0. \end{align*}
Here, the first inequality holds since the support of
 $a^+ + b_{S^+}$
and
$a^+ + b_{S^+}$
and
 $b_{S^{+}_{c}} -a^-$
are disjoint. The second inequality holds because
$b_{S^{+}_{c}} -a^-$
are disjoint. The second inequality holds because
 $-\sqrt {\tfrac {c\kappa }{2}}\tfrac {1}{\|a^+\|_{2}}a^+$
is supported on
$-\sqrt {\tfrac {c\kappa }{2}}\tfrac {1}{\|a^+\|_{2}}a^+$
is supported on
 $S^+$
, it is a feasible point, and because the standard optimisation problem
$S^+$
, it is a feasible point, and because the standard optimisation problem
 \begin{equation*} \min _{b \in \mathbb{R}^n} \|a - b\|_2^2 \text{ s.t. } \|b\|_2 \leq r, \end{equation*}
\begin{equation*} \min _{b \in \mathbb{R}^n} \|a - b\|_2^2 \text{ s.t. } \|b\|_2 \leq r, \end{equation*}
has solution
 $ b = \min \big\{1, \frac {r}{\|a\|_2}\big\}a.$
Setting
$ b = \min \big\{1, \frac {r}{\|a\|_2}\big\}a.$
Setting
 $r = \sqrt {\frac {c \kappa }{2}}$
gives the second inequality above. Finally, the last inequality holds since
$r = \sqrt {\frac {c \kappa }{2}}$
gives the second inequality above. Finally, the last inequality holds since
 $\|a^+\|_{2} \gt \sqrt {\frac {c\kappa }{2}}$
.
$\|a^+\|_{2} \gt \sqrt {\frac {c\kappa }{2}}$
.
From symmetry, it is clear that if
 $\|a^{-}\|_{2}^{2}\leq c\kappa /2$
, then the objective function of (Q 2
) is zero, and if
$\|a^{-}\|_{2}^{2}\leq c\kappa /2$
, then the objective function of (Q 2
) is zero, and if
 $\|a^{-}\|_{2}^{2}\gt c\kappa /2$
, we have that
$\|a^{-}\|_{2}^{2}\gt c\kappa /2$
, we have that
 \begin{equation*} \min _{b\in {\mathbb{R}}^N}\left \{\|\max \{-a+b,0\}\|_{2}^{2} \,:\, \|b\|_{2}^{2} \leq c\kappa /2\right \} = \frac {c\kappa }{2} + \|a^-\|_{2}\left(\|a^-\|_{2} - \sqrt {2c\kappa }\right) \gt 0.\end{equation*}
\begin{equation*} \min _{b\in {\mathbb{R}}^N}\left \{\|\max \{-a+b,0\}\|_{2}^{2} \,:\, \|b\|_{2}^{2} \leq c\kappa /2\right \} = \frac {c\kappa }{2} + \|a^-\|_{2}\left(\|a^-\|_{2} - \sqrt {2c\kappa }\right) \gt 0.\end{equation*}
Next, observe that due to assumption (i), we have that
 \begin{equation} \begin{split} &\|\max \{a+b^1\}\|_{2}^{2} + \|\max \{-a+b^2,0\}\|_{2}^{2} \\ &\geq \min _{b\in {\mathbb{R}}^N} \left \{ \|\max \{a + b,0\}\|_{2}^{2} \,:\, \|b\|_{2}^{2} \leq c\kappa /2 \right \} + \min _{b\in {\mathbb{R}}^N} \left \{ \|\max \{-a + b,0\}\|_{2}^{2} \,:\, \|b\|_{2}^{2} \leq c\kappa /2 \right \} \end{split} \end{equation}
\begin{equation} \begin{split} &\|\max \{a+b^1\}\|_{2}^{2} + \|\max \{-a+b^2,0\}\|_{2}^{2} \\ &\geq \min _{b\in {\mathbb{R}}^N} \left \{ \|\max \{a + b,0\}\|_{2}^{2} \,:\, \|b\|_{2}^{2} \leq c\kappa /2 \right \} + \min _{b\in {\mathbb{R}}^N} \left \{ \|\max \{-a + b,0\}\|_{2}^{2} \,:\, \|b\|_{2}^{2} \leq c\kappa /2 \right \} \end{split} \end{equation}
From assumption (ii), we have that
 $\|a\|_{2}^{2} = \|a^+\|_{2}^{2} + \|a^-\|_{2}^{2} = 2\kappa$
, which implies that we cannot have that
$\|a\|_{2}^{2} = \|a^+\|_{2}^{2} + \|a^-\|_{2}^{2} = 2\kappa$
, which implies that we cannot have that
 $\|a^+\|_{2}^{2} \leq c\kappa /2$
and
$\|a^+\|_{2}^{2} \leq c\kappa /2$
and
 $\|a^-\|_{2}^{2} \leq c\kappa /2$
at the same time. Thus, to bound the expression on the right-hand side in (7.3), we need to consider the three cases:
$\|a^-\|_{2}^{2} \leq c\kappa /2$
at the same time. Thus, to bound the expression on the right-hand side in (7.3), we need to consider the three cases:
-
(A)
$\|a^+\|_{2}^{2} \gt c\kappa /2$
and
$\|a^-\|_{2}^{2} \gt c\kappa /2$
, -
(B)
$\|a^-\|_{2}^{2} \leq c\kappa /2$
, -
(C)
$\|a^+\|_{2}^{2} \leq c\kappa /2$
.




We start by considering (A), so suppose that this holds. Observe that
 $\|a^-\|_{2} =\sqrt {2\kappa - \|a^+\|_{2}^{2}}$
since
$\|a^-\|_{2} =\sqrt {2\kappa - \|a^+\|_{2}^{2}}$
since
 $\|a\|_{2}^{2} = 2\kappa$
and that
$\|a\|_{2}^{2} = 2\kappa$
and that
 $c\kappa /2 \lt \|a^+\|_{2}^{2} \lt 2\kappa - c\kappa /2$
due to assumption (A). From above, we know that the minimum value of both (Q 1
) and (Q 2
) are positive in this case. Combining this fact with (7.3), we see that
$c\kappa /2 \lt \|a^+\|_{2}^{2} \lt 2\kappa - c\kappa /2$
due to assumption (A). From above, we know that the minimum value of both (Q 1
) and (Q 2
) are positive in this case. Combining this fact with (7.3), we see that
 \begin{align*} &\|\max \{a+b^1\}\|_{2}^{2} + \|\max \{-a+b^2,0\}\|_{2}^{2} \\ &\geq c\kappa + \|a^+\|_{2} \left ( \|a^+\|_{2} - \sqrt {2c\kappa }\right ) + \|a^-\|_{2} \left ( \|a^-\|_{2} - \sqrt {2c\kappa }\right ) \\ &= c\kappa + \|a^+\|_{2} \left ( \|a^+\|_{2} - \sqrt {2c\kappa }\right ) + \sqrt {2\kappa - \|a^+\|_{2}^2} \left (\sqrt {2\kappa - \|a^+\|_{2}^2} - \sqrt {2c\kappa }\right ) \\ &= (2+c)\kappa - \sqrt {2c\kappa }\left ( \|a^+\|_{2} + \sqrt {2\kappa - \|a^+\|_{2}^{2}} \right ) \\ &\geq (2+c)\kappa - \sqrt {8c}\kappa = \big(2+c-\sqrt {8c}\big)\kappa . \end{align*}
\begin{align*} &\|\max \{a+b^1\}\|_{2}^{2} + \|\max \{-a+b^2,0\}\|_{2}^{2} \\ &\geq c\kappa + \|a^+\|_{2} \left ( \|a^+\|_{2} - \sqrt {2c\kappa }\right ) + \|a^-\|_{2} \left ( \|a^-\|_{2} - \sqrt {2c\kappa }\right ) \\ &= c\kappa + \|a^+\|_{2} \left ( \|a^+\|_{2} - \sqrt {2c\kappa }\right ) + \sqrt {2\kappa - \|a^+\|_{2}^2} \left (\sqrt {2\kappa - \|a^+\|_{2}^2} - \sqrt {2c\kappa }\right ) \\ &= (2+c)\kappa - \sqrt {2c\kappa }\left ( \|a^+\|_{2} + \sqrt {2\kappa - \|a^+\|_{2}^{2}} \right ) \\ &\geq (2+c)\kappa - \sqrt {8c}\kappa = \big(2+c-\sqrt {8c}\big)\kappa . \end{align*}
Where the last inequality follows from the fact that function
 $f(x) = x + \sqrt {2\kappa - x^2}$
on the domain
$f(x) = x + \sqrt {2\kappa - x^2}$
on the domain
 $\sqrt {c\kappa /2} \lt x \lt \sqrt {2\kappa - c\kappa /2}$
attains it maximum in
$\sqrt {c\kappa /2} \lt x \lt \sqrt {2\kappa - c\kappa /2}$
attains it maximum in
 $x = \sqrt {\kappa }$
. This shows the lower bound in (7.2), whenever (A) holds.
$x = \sqrt {\kappa }$
. This shows the lower bound in (7.2), whenever (A) holds.
Now, suppose that (B) holds. Since
 $\|a^-\|_{2}^2 \leq c\kappa /2$
, we have that
$\|a^-\|_{2}^2 \leq c\kappa /2$
, we have that
 $\|a^+\|_{2} \geq \sqrt {2\kappa - c\kappa /2} \gt \sqrt {c\kappa /2}$
. Furthermore, since
$\|a^+\|_{2} \geq \sqrt {2\kappa - c\kappa /2} \gt \sqrt {c\kappa /2}$
. Furthermore, since
 $\|a^-\|_{2}^2 \leq c\kappa /2$
we know that the minimum value of (Q 2
) is zero, and the lower bound for (7.3) becomes
$\|a^-\|_{2}^2 \leq c\kappa /2$
we know that the minimum value of (Q 2
) is zero, and the lower bound for (7.3) becomes
 \begin{align*} \|\max \{a+b^1\}\|_{2}^{2} + \|\max \{-a+b^2,0\}\|_{2}^{2} &\geq \frac {c\kappa }{2} + \|a^+\|_{2} \left ( \|a^+\|_{2} - \sqrt {2c\kappa }\right ) \geq \left ( 2-\sqrt {4c-c^2}\right ) \kappa \\ &\geq \big(2 + c -\sqrt {8c}\big)\kappa \end{align*}
\begin{align*} \|\max \{a+b^1\}\|_{2}^{2} + \|\max \{-a+b^2,0\}\|_{2}^{2} &\geq \frac {c\kappa }{2} + \|a^+\|_{2} \left ( \|a^+\|_{2} - \sqrt {2c\kappa }\right ) \geq \left ( 2-\sqrt {4c-c^2}\right ) \kappa \\ &\geq \big(2 + c -\sqrt {8c}\big)\kappa \end{align*}
where we used that
 $\|a^+\|_{2} \geq \sqrt {2\kappa - c\kappa /2}$
for the second to last inequality. By symmetry, we get the same lower bound if we assume that (C) holds. We, therefore, conclude that the lower bound in (7.2) holds.
$\|a^+\|_{2} \geq \sqrt {2\kappa - c\kappa /2}$
for the second to last inequality. By symmetry, we get the same lower bound if we assume that (C) holds. We, therefore, conclude that the lower bound in (7.2) holds.
7.2. Breakdown epsilons – the key to proving the impossibility statements
The key to proving the impossibility statements in Theorem 4.2 is via the breakdown epsilons introduced in [Reference Bastounis, Hansen and Vlačić11]. In an intuitive sense, we have the following definition: The strong breakdown epsilon is the largest
 $\epsilon$
, for which any algorithm fails to achieve
$\epsilon$
, for which any algorithm fails to achieve
 $\epsilon$
accuracy on a given computational problem for at least one input. We now present the precise versions of the breakdown epsilons, both in the deterministic and randomised setting.
$\epsilon$
accuracy on a given computational problem for at least one input. We now present the precise versions of the breakdown epsilons, both in the deterministic and randomised setting.
Definition 7.3 (Strong breakdown epsilons [Reference Bastounis, Hansen and Vlačić11]). Given a computational problem
 $\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
, we define
$\{\Xi , \Omega , \mathcal{M}, \Lambda \}$
, we define
-
(i) the strong breakdown epsilon by
\begin{equation*} \epsilon _{\mathrm{B}}^{\mathrm{s}}\,:\!=\, \sup \{\epsilon \geq 0 \,:\, \forall \text{ general algorithms } \Gamma , \exists \iota \in \Omega \text{ such that }\mathrm{dist}_{\mathcal{M}}(\Gamma (\iota ), \Xi (\iota )) \gt \epsilon \}, \: \text{and} \end{equation*}
-
(ii) the probabilistic strong breakdown epsilon by
$\epsilon ^{\mathrm{s}}_{\mathbb{P}\mathrm{B}} \colon [0,1)\to {\mathbb{R}}$
by
\begin{equation*} \epsilon _{\mathbb{P}\mathrm{B}}^{\mathrm{s}}(\mathrm{p}) = \sup \left\{\epsilon \geq 0 \,:\, \forall \, \Gamma ^{\mathrm{ran}} \in \mathrm{RGA} \,\,\exists \, \iota \in \Omega \text{ such that } \mathbb{P}_{\iota }\left(\mathrm{dist}_{\mathcal{M}}\left(\Gamma ^{\mathrm{ran}}_{\iota },\Xi (\iota )\right) \gt \epsilon \right) \gt \mathrm{p}\right\}, \end{equation*}



where
 $\mathrm{dist}_{\mathcal{M}}(\Gamma (\iota ), \Xi (\iota )) = \inf _{\xi \in \Xi (\iota )}d_{{\mathcal{M}}}(\Gamma (\iota ), \xi )$
.
$\mathrm{dist}_{\mathcal{M}}(\Gamma (\iota ), \Xi (\iota )) = \inf _{\xi \in \Xi (\iota )}d_{{\mathcal{M}}}(\Gamma (\iota ), \xi )$
.
We need the following important proposition from [Reference Bastounis, Hansen and Vlačić11] to prove the computational breakdown in Theorem 6.8.
Proposition 7.4 (Proposition 9.5 in [Reference Bastounis, Hansen and Vlačić11]). Let
 $\{ \Xi , \Omega , {\mathcal{M}}, \Lambda \}$
be a computational problem with
$\{ \Xi , \Omega , {\mathcal{M}}, \Lambda \}$
be a computational problem with
 $\Lambda = \{ f_k \: | \: k \in \mathbb{N}, \: k \leq | \Lambda | \: \}$
countable. Suppose that there are two sequences
$\Lambda = \{ f_k \: | \: k \in \mathbb{N}, \: k \leq | \Lambda | \: \}$
countable. Suppose that there are two sequences
 $\{\iota _n^1\}_{n \in \mathbb{N}},\{\iota _n^2\}_{n \in \mathbb{N}} \subseteq \Omega$
satisfying the following conditions:
$\{\iota _n^1\}_{n \in \mathbb{N}},\{\iota _n^2\}_{n \in \mathbb{N}} \subseteq \Omega$
satisfying the following conditions:
-
(a) There are sets
$S_1,S_2 \subseteq {\mathcal{M}}$
and
$\kappa \gt 0$
such that
$\inf _{x_1 \in S_1,x_2 \in S_2}d_{{\mathcal{M}}}(x_1,x_2) \geq \kappa$
and
$\Xi (\iota _n^j) \subseteq S_j$
for
$j = 1,2.$
-
(b) For every
$k \leq | \Lambda |$
, there is a
$c_k \in {\mathbb{C}}$
such that
$|f_k(\iota _n^j)-c_k| \leq 1/4^n$
for all
$n \in \mathbb{N}$
and
$j = 1,2$
. -
(c) There is
$\iota ^0 \in \Omega$
such that for every
$k \leq | \Lambda |$
we have that
$b)$
is satisfied with
$c_k = f_k(\iota ^0)$
. -
(d) There is
$\iota ^0 \in \Omega$
for which condition
$c)$
holds and additionally
$\iota _n^2 = \iota ^0$
, for all
$n \in \mathbb{N}$
.


















Then there exists
 $\tilde {\Lambda } \in \mathcal{L}(\Lambda )$
such that
$\tilde {\Lambda } \in \mathcal{L}(\Lambda )$
such that
 $\epsilon _B^s \geq \epsilon _{\mathbb{P}B}^s(p) \geq \kappa /2$
for
$\epsilon _B^s \geq \epsilon _{\mathbb{P}B}^s(p) \geq \kappa /2$
for
 $p \in [0,1/2)$
for the computational problem
$p \in [0,1/2)$
for the computational problem
 $\{ \Xi , \Omega , {\mathcal{M}}, \tilde {\Lambda } \}$
.
$\{ \Xi , \Omega , {\mathcal{M}}, \tilde {\Lambda } \}$
.
Remark 7.5. Note that the above proposition holds also in the Markov model. Since this is the main mechanism for the impossibility result in our main results, Theorem 4.2 holds also in the Markov model. The mathematical theory for converting between the two models (Markov model and computable
 $\Delta _1$
-information) was developed in [Reference Ceĭtin25, Reference Kreisel, Lacombe, Shoenfield and Heyting51].
$\Delta _1$
-information) was developed in [Reference Ceĭtin25, Reference Kreisel, Lacombe, Shoenfield and Heyting51].
We remind the reader that we are interested in proving that the computational breakdown for any training set
 $\mathcal{T}$
happens at a point contained in
$\mathcal{T}$
happens at a point contained in
 $\pi _2({\mathcal{T}})$
, where
$\pi _2({\mathcal{T}})$
, where
 $\pi _2({\mathcal{T}}) = \{y \in {\mathbb{R}}^m \: : \: (x,y) \in {\mathcal{T}} \}$
. More precisely, we wish to prove that for any
$\pi _2({\mathcal{T}}) = \{y \in {\mathbb{R}}^m \: : \: (x,y) \in {\mathcal{T}} \}$
. More precisely, we wish to prove that for any
 $\kappa \in (0,1/8)$
, there exists domains
$\kappa \in (0,1/8)$
, there exists domains
 $\Omega$
such that, for any algorithm
$\Omega$
such that, for any algorithm
 $\Gamma$
, there exists at least one pair
$\Gamma$
, there exists at least one pair
 $({\mathcal{T}}, \theta _{\Phi }) \in \Omega$
such that
$({\mathcal{T}}, \theta _{\Phi }) \in \Omega$
such that
 $\text{dist}_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),\Xi _{\beta }({\mathcal{T}},\theta _{\Phi })) \,:\!=\, \inf _{(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }({\mathcal{T}},\theta _{\Phi })}d_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),(\underline {\phi },\overline {\phi })) \geq \kappa /2$
, with
$\text{dist}_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),\Xi _{\beta }({\mathcal{T}},\theta _{\Phi })) \,:\!=\, \inf _{(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }({\mathcal{T}},\theta _{\Phi })}d_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),(\underline {\phi },\overline {\phi })) \geq \kappa /2$
, with
 \begin{align} d_{{\mathcal{T}}} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) = \max \left \{ \sup _{y \in \pi _2({\mathcal{T}})} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in \pi _2({\mathcal{T}})} \| \underline {\phi }(y) - \underline {\psi }(y) \|_2^2 \right \}. \end{align}
\begin{align} d_{{\mathcal{T}}} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) = \max \left \{ \sup _{y \in \pi _2({\mathcal{T}})} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in \pi _2({\mathcal{T}})} \| \underline {\phi }(y) - \underline {\psi }(y) \|_2^2 \right \}. \end{align}
We therefore proceed by proving the computational breakdown for the alternative inverse problem
 $\{\Xi _{\beta }, \Omega , {\mathcal{M}}', \hat \Lambda \}$
where
$\{\Xi _{\beta }, \Omega , {\mathcal{M}}', \hat \Lambda \}$
where
 ${\mathcal{M}}' = {\mathcal{N} \mathcal{N}}_{\Phi }^u \times {\mathcal{N} \mathcal{N}}_{\Phi }^o$
, but with the metric
${\mathcal{M}}' = {\mathcal{N} \mathcal{N}}_{\Phi }^u \times {\mathcal{N} \mathcal{N}}_{\Phi }^o$
, but with the metric
 $d_{{\mathcal{M}}}((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi }))$
, introduced in Eq. (6.3), replaced by the metric
$d_{{\mathcal{M}}}((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi }))$
, introduced in Eq. (6.3), replaced by the metric
 $d_{{\mathcal{M}}'}((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi }))$
given by
$d_{{\mathcal{M}}'}((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi }))$
given by
 \begin{align} d_{{\mathcal{M}}'} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) \,:\!=\, \max \left \{ \sup _{y \in \mathcal{F}_{\Omega }} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in \mathcal{F}_{\Omega }} \| \underline {\phi }(y) - \underline {\psi }(y) \|_2^2 \right \}, \end{align}
\begin{align} d_{{\mathcal{M}}'} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) \,:\!=\, \max \left \{ \sup _{y \in \mathcal{F}_{\Omega }} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in \mathcal{F}_{\Omega }} \| \underline {\phi }(y) - \underline {\psi }(y) \|_2^2 \right \}, \end{align}
with
 $\mathcal{F}_{\Omega } = \bigcap _{{\mathcal{T}} \in \Omega }\pi _2({\mathcal{T}})$
, where we identify the neural networks that are equal on
$\mathcal{F}_{\Omega } = \bigcap _{{\mathcal{T}} \in \Omega }\pi _2({\mathcal{T}})$
, where we identify the neural networks that are equal on
 $\mathcal{F}_{\Omega }$
. We observe that proving that
$\mathcal{F}_{\Omega }$
. We observe that proving that
 $\epsilon _{\mathrm{B}}^s \gt \kappa /2$
for
$\epsilon _{\mathrm{B}}^s \gt \kappa /2$
for
 $\{\Xi _{\beta }, \Omega , {\mathcal{M}}', \hat \Lambda \}$
immediately implies that there exists at least one pair
$\{\Xi _{\beta }, \Omega , {\mathcal{M}}', \hat \Lambda \}$
immediately implies that there exists at least one pair
 $({\mathcal{T}}, \theta _{\Phi }) \in \Omega$
such that
$({\mathcal{T}}, \theta _{\Phi }) \in \Omega$
such that
 $\text{dist}_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),\Xi _{\beta }({\mathcal{T}},\theta _{\Phi })) \geq \kappa /2$
, when reading inexact input.
$\text{dist}_{{\mathcal{T}}}(\Gamma ({\mathcal{T}}, \theta _{\Phi }),\Xi _{\beta }({\mathcal{T}},\theta _{\Phi })) \geq \kappa /2$
, when reading inexact input.
Proposition 7.6. Let
 $m,N \in \mathbb{N}$
with
$m,N \in \mathbb{N}$
with
 $N \geq 2$
, and let
$N \geq 2$
, and let
 $A \in {\mathbb{R}}^{m\times N}$
be such that
$A \in {\mathbb{R}}^{m\times N}$
be such that
 $1\leq \mathrm{rank}(A) \lt N$
. Let
$1\leq \mathrm{rank}(A) \lt N$
. Let
 $\ell \geq 2$
,
$\ell \geq 2$
,
 $\kappa \in (0,1/8)$
and let
$\kappa \in (0,1/8)$
and let
 ${\mathcal{N} \mathcal{N}}_{\ell }$
be a class of neural networks that satisfies Assumption 2.1
. Then for any
${\mathcal{N} \mathcal{N}}_{\ell }$
be a class of neural networks that satisfies Assumption 2.1
. Then for any
 $\beta \in (0, \sqrt {\kappa }/(4\sqrt {2N}))$
, there exists infinitely many model classes
$\beta \in (0, \sqrt {\kappa }/(4\sqrt {2N}))$
, there exists infinitely many model classes
 ${\mathcal{U}}_1 \subseteq B_1^N(0)$
, and for each model class, infinitely many choices for
${\mathcal{U}}_1 \subseteq B_1^N(0)$
, and for each model class, infinitely many choices for
 $\Omega$
, giving rise to infinitely many computational problems
$\Omega$
, giving rise to infinitely many computational problems
 $\{\Xi _{\beta },\Omega ,\mathcal{M},\Lambda \}$
, where the objects are as described in Equation (4.2) and Equation (6.2)–Equation (6.4), such that there exists a set
$\{\Xi _{\beta },\Omega ,\mathcal{M},\Lambda \}$
, where the objects are as described in Equation (4.2) and Equation (6.2)–Equation (6.4), such that there exists a set
 $\hat {\Lambda } \in \mathcal{L}^1(\Lambda )$
, giving
$\hat {\Lambda } \in \mathcal{L}^1(\Lambda )$
, giving
 $\Delta _1$
-information, such that
$\Delta _1$
-information, such that
 $\epsilon _{\mathrm{B}}^s \geq \epsilon _{\mathbb{P}\mathrm{B}}^s(p) \geq \kappa /2$
for
$\epsilon _{\mathrm{B}}^s \geq \epsilon _{\mathbb{P}\mathrm{B}}^s(p) \geq \kappa /2$
for
 $p \in [0,1/2)$
for the computational problem
$p \in [0,1/2)$
for the computational problem
 $\{\Xi _{\beta }, \Omega , {\mathcal{M}}', \hat \Lambda \}$
, where
$\{\Xi _{\beta }, \Omega , {\mathcal{M}}', \hat \Lambda \}$
, where
 ${\mathcal{M}}'$
is the metric defined in Eq. (7.5).
${\mathcal{M}}'$
is the metric defined in Eq. (7.5).
Proof. We prove the above result by constructing a set
 $\mathcal{U}_1\subset {\mathbb{R}}^N$
and a domain
$\mathcal{U}_1\subset {\mathbb{R}}^N$
and a domain
 $\Omega$
, as described in Eq. (4.2), with sequences
$\Omega$
, as described in Eq. (4.2), with sequences
 $\{(\iota ^1_{n}, \Phi _n^1)\}_{n \in \mathbb{N}}, \{(\iota ^2_{n}, \Phi _n^2)\}_{n \in \mathbb{N}} \subseteq \Omega$
that satisfy the following conditions:
$\{(\iota ^1_{n}, \Phi _n^1)\}_{n \in \mathbb{N}}, \{(\iota ^2_{n}, \Phi _n^2)\}_{n \in \mathbb{N}} \subseteq \Omega$
that satisfy the following conditions:
-
(a) There are sets
$S^1,S^2\subset \mathcal{M}'$
such that
$\inf _{(\underline {\phi },\overline {\phi })\in S^1, (\underline {\psi },\overline {\psi })\in S^2} d_{\mathcal{M}'}((\underline {\phi },\overline {\phi }), (\underline {\psi },\overline {\psi }))\geq \kappa$
and
$\Xi _{\beta }(\iota ^j_{n}, \Phi _n^j)\subset S^{j}$
for
$j=1,2$
. -
(b) For every
$k \in |\Lambda |$
, there is a
$c_{k} \in {\mathbb{C}}$
such that
$|f_{k}(\iota ^j_{n},\Phi _n^j) - c_k|\leq 1/4^n$
, for
$j=1,2$
and all
$n\in \mathbb{N}$
. -
(c) There is an
$(\iota ^0,\Phi ^0) \in T_{\ell ,\mathcal{U}_1} \times \mathcal{W}(\iota _0, {\mathcal{N} \mathcal{N}}_{\ell })$
such that for every
$k \leq |\Lambda |$
we have that (b) satisfies with
$c_k = f_{k}(\iota ^0, \Phi ^0)$
. -
(d) There is an
$(\iota ^0, \Phi ^0) \in T_{\ell ,\mathcal{U}_1} \times \mathcal{W}(\iota ^0,{\mathcal{N} \mathcal{N}}_{\ell })$
for which condition (c) holds and additionally
$(\iota ^2_{n}, \Phi _n^2) = (\iota ^0,\Phi ^0)$
, for all
$n \in \mathbb{N}$
.















Then it follows from Proposition 7.4 that there exists a
 $\hat \Lambda \in \mathcal{L}^1(\Lambda )$
, such that
$\hat \Lambda \in \mathcal{L}^1(\Lambda )$
, such that
 $\epsilon _{\mathrm{B}}^s \geq \epsilon _{\mathbb{P}\mathrm{B}}^s(p) \geq \kappa /2$
for
$\epsilon _{\mathrm{B}}^s \geq \epsilon _{\mathbb{P}\mathrm{B}}^s(p) \geq \kappa /2$
for
 $p \in [0,1/2)$
for the computational problem
$p \in [0,1/2)$
for the computational problem
 $\{\Xi _{\beta }, \Omega ,{\mathcal{M}}', \hat \Lambda \}$
.
$\{\Xi _{\beta }, \Omega ,{\mathcal{M}}', \hat \Lambda \}$
.
We proceed by constructing
 $\mathcal{U}_1$
and start by making a few observations. The kernel of
$\mathcal{U}_1$
and start by making a few observations. The kernel of
 $A$
must be non-trivial since
$A$
must be non-trivial since
 $\mathrm{rank}(A) \lt N$
. We can, therefore, pick a non-zero vector
$\mathrm{rank}(A) \lt N$
. We can, therefore, pick a non-zero vector
 $v \in \ker (A)$
with squared norm
$v \in \ker (A)$
with squared norm
 $\|v\|_{2}^{2} =8\kappa$
. Furthermore, since
$\|v\|_{2}^{2} =8\kappa$
. Furthermore, since
 $\mathrm{rank}(A) \geq 1$
, we can pick a non-zero vector
$\mathrm{rank}(A) \geq 1$
, we can pick a non-zero vector
 $w \in \ker (A)^{\perp }$
with
$w \in \ker (A)^{\perp }$
with
 $\|w\|_2 = (3-2\sqrt {2})\kappa$
.
$\|w\|_2 = (3-2\sqrt {2})\kappa$
.
Let
 $\mathcal{S} = \{tw \,:\, t \in [-1,-1/2]\}$
and let the model set
$\mathcal{S} = \{tw \,:\, t \in [-1,-1/2]\}$
and let the model set
 $\mathcal{U}_1 \,:\!=\, \{ v+tw \,:\, t \in [0,1]\} \cup \{0\}\cup \mathcal{S}$
. For
$\mathcal{U}_1 \,:\!=\, \{ v+tw \,:\, t \in [0,1]\} \cup \{0\}\cup \mathcal{S}$
. For
 $\ell \gt 2$
let
$\ell \gt 2$
let
 $\mathcal{T}_{b} \subset \mathcal{S} \times A(\mathcal{S})$
be a set with cardinality
$\mathcal{T}_{b} \subset \mathcal{S} \times A(\mathcal{S})$
be a set with cardinality
 $\ell -2$
, where all of the first components are distinct. We note that this implies that all the second components are distinct as well, since
$\ell -2$
, where all of the first components are distinct. We note that this implies that all the second components are distinct as well, since
 $\mathcal{S} \subset \ker (A)^{\perp }$
. If
$\mathcal{S} \subset \ker (A)^{\perp }$
. If
 $\ell =2$
, we let
$\ell =2$
, we let
 $\mathcal{T}_b =\emptyset$
. Given the above setup, we can now define the two sequences
$\mathcal{T}_b =\emptyset$
. Given the above setup, we can now define the two sequences
 $\{\iota _n^1\}_{n \in \mathbb{N}}$
and
$\{\iota _n^1\}_{n \in \mathbb{N}}$
and
 $\{\iota _n^2\}_{n \in \mathbb{N}}$
as follows. Let
$\{\iota _n^2\}_{n \in \mathbb{N}}$
as follows. Let
 \begin{equation} \iota _n^1 = \left({\mathcal{T}}_b,(0,0),\left({v} \!+ \! \frac {1}{4^n}w,\frac {1}{4^n }Aw\right)\right) \quad \text{and} \quad \iota _n^2 = ({\mathcal{T}}_b,(0,0),({v}, 0)), \quad n \in \mathbb{N}. \end{equation}
\begin{equation} \iota _n^1 = \left({\mathcal{T}}_b,(0,0),\left({v} \!+ \! \frac {1}{4^n}w,\frac {1}{4^n }Aw\right)\right) \quad \text{and} \quad \iota _n^2 = ({\mathcal{T}}_b,(0,0),({v}, 0)), \quad n \in \mathbb{N}. \end{equation}
We observe that the elements in
 $\iota _n^1$
and
$\iota _n^1$
and
 $\iota _n^2$
are listed such that all the equal elements land on the same index and such that
$\iota _n^2$
are listed such that all the equal elements land on the same index and such that
 $(x^{(\ell )}, A(x^{(\ell )})) = ({v} \!+ \! \frac {1}{4^n}w,\frac {1}{4^n }Aw) \in \iota _n^1$
and
$(x^{(\ell )}, A(x^{(\ell )})) = ({v} \!+ \! \frac {1}{4^n}w,\frac {1}{4^n }Aw) \in \iota _n^1$
and
 $(x^{(\ell )}, A(x^{(\ell )})) = ({v}, 0) \in \iota _n^2$
. It is clear that
$(x^{(\ell )}, A(x^{(\ell )})) = ({v}, 0) \in \iota _n^2$
. It is clear that
 $\iota _n^j \subseteq T_{\ell , \mathcal{U}_1}$
for all
$\iota _n^j \subseteq T_{\ell , \mathcal{U}_1}$
for all
 $n \in \mathbb{N}$
and
$n \in \mathbb{N}$
and
 $j = 1,2$
, and that
$j = 1,2$
, and that
 ${\mathcal{U}}_1 \subseteq B_1^N(0)$
.
${\mathcal{U}}_1 \subseteq B_1^N(0)$
.
Next, since, by Assumption 2.1,
 ${\mathcal{N} \mathcal{N}}_{\ell }$
is an
${\mathcal{N} \mathcal{N}}_{\ell }$
is an
 $\ell$
-interpolatory class of neural networks and
$\ell$
-interpolatory class of neural networks and
 $\iota _n^1$
consists of
$\iota _n^1$
consists of
 $\ell$
distinct points, there exists a neural network
$\ell$
distinct points, there exists a neural network
 $\Phi _n^1 \in {\mathcal{N} \mathcal{N}}_{\ell }$
that interpolates all the points in
$\Phi _n^1 \in {\mathcal{N} \mathcal{N}}_{\ell }$
that interpolates all the points in
 $\iota _n^1$
for each
$\iota _n^1$
for each
 $n \in \mathbb{N}$
. It then follows from the definition of
$n \in \mathbb{N}$
. It then follows from the definition of
 $\mathcal{W}(\iota _n^1,{\mathcal{N} \mathcal{N}}_{\ell })$
in Eq. (2.8) that
$\mathcal{W}(\iota _n^1,{\mathcal{N} \mathcal{N}}_{\ell })$
in Eq. (2.8) that
 $\Phi _n^1 \in \mathcal{W}(\iota _n^1,{\mathcal{N} \mathcal{N}}_{\ell })$
for all
$\Phi _n^1 \in \mathcal{W}(\iota _n^1,{\mathcal{N} \mathcal{N}}_{\ell })$
for all
 $n \in \mathbb{N}$
. In the case of
$n \in \mathbb{N}$
. In the case of
 $\iota _n^2$
, the map
$\iota _n^2$
, the map
 ${\mathcal{V}}_{\iota _n^2}(y)$
in Eq. (2.7) is multi-valued at the point
${\mathcal{V}}_{\iota _n^2}(y)$
in Eq. (2.7) is multi-valued at the point
 $y = 0$
. However, we observe that any map
$y = 0$
. However, we observe that any map
 $\Psi _1 \in {\mathcal{N} \mathcal{N}}_{\ell }$
that interpolates all the points in
$\Psi _1 \in {\mathcal{N} \mathcal{N}}_{\ell }$
that interpolates all the points in
 ${\mathcal{T}}_b$
and that satisfies
${\mathcal{T}}_b$
and that satisfies
 $\Psi _1(0) = 0$
has the property that
$\Psi _1(0) = 0$
has the property that
 $\Psi _1 \in \mathcal{W}(\iota _n^2,{\mathcal{N} \mathcal{N}}_{\ell })$
. In particular, this gives us that
$\Psi _1 \in \mathcal{W}(\iota _n^2,{\mathcal{N} \mathcal{N}}_{\ell })$
. In particular, this gives us that
 $\Phi _n^1 \in \mathcal{W}(\iota _n^2,{\mathcal{N} \mathcal{N}}_{\ell })$
; therefore, by simply setting
$\Phi _n^1 \in \mathcal{W}(\iota _n^2,{\mathcal{N} \mathcal{N}}_{\ell })$
; therefore, by simply setting
 $\Phi _n^2 = \Phi _n^1$
for each
$\Phi _n^2 = \Phi _n^1$
for each
 $n \in \mathbb{N}$
, we may conclude that
$n \in \mathbb{N}$
, we may conclude that
 $\Phi _n^2 \in \mathcal{W}(\iota _n^2,{\mathcal{N} \mathcal{N}}_{\ell })$
for each
$\Phi _n^2 \in \mathcal{W}(\iota _n^2,{\mathcal{N} \mathcal{N}}_{\ell })$
for each
 $n \in \mathbb{N}$
.
$n \in \mathbb{N}$
.
With this in place, we let
 $\Omega = \{(\iota _n^1,\Phi _n^1)\}_{n \in N} \cup \{(\iota _n^2, \Phi _n^2)\}_{n \in \mathbb{N}}$
in what follows. By the arbitrary choice of the elements in
$\Omega = \{(\iota _n^1,\Phi _n^1)\}_{n \in N} \cup \{(\iota _n^2, \Phi _n^2)\}_{n \in \mathbb{N}}$
in what follows. By the arbitrary choice of the elements in
 $\mathcal{T}_b$
and
$\mathcal{T}_b$
and
 $w \in \ker (A)^{\bot }$
, it is clear that there exists uncountably many choices for the model class
$w \in \ker (A)^{\bot }$
, it is clear that there exists uncountably many choices for the model class
 ${\mathcal{U}}_1$
, and for each choice of
${\mathcal{U}}_1$
, and for each choice of
 ${\mathcal{U}}_1$
, there exists uncountably many choices for
${\mathcal{U}}_1$
, there exists uncountably many choices for
 $\Omega$
.
$\Omega$
.
With the above sequences well defined, we proceed by showing that these sequences satisfy the claims in (A)–(d) above. We start by considering (A), with
 $S^j = \bigcup _{n=1}^{\infty } \Xi _{\beta }(\iota _{n}^j,\Phi _n^j)$
, for
$S^j = \bigcup _{n=1}^{\infty } \Xi _{\beta }(\iota _{n}^j,\Phi _n^j)$
, for
 $j=1,2$
. We observe that any pair of
$j=1,2$
. We observe that any pair of
 $\ell$
-interpolatory NNs, which interpolates all the training data in
$\ell$
-interpolatory NNs, which interpolates all the training data in
 $\iota ^{1}_{n}$
, attains zero training loss on
$\iota ^{1}_{n}$
, attains zero training loss on
 $F_{\iota _{n}^1,\beta }$
. In particular, this implies that any pair
$F_{\iota _{n}^1,\beta }$
. In particular, this implies that any pair
 $(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }(\iota _{n}^{1}, \Phi _n^1)$
interpolates the data in
$(\underline {\phi },\overline {\phi }) \in \Xi _{\beta }(\iota _{n}^{1}, \Phi _n^1)$
interpolates the data in
 $\iota _{n}^{1}$
.
$\iota _{n}^{1}$
.
Next, we consider the constant sequence
 $\iota _{n}^{2}$
where both
$\iota _{n}^{2}$
where both
 $(0,0) \in \iota _{n}^{2}$
and
$(0,0) \in \iota _{n}^{2}$
and
 $(v,0)\in \iota _{n}^{2}$
have identical
$(v,0)\in \iota _{n}^{2}$
have identical
 $y$
-coordinates, and all other other
$y$
-coordinates, and all other other
 $y$
-coordinates are distinct. Furthermore, since
$y$
-coordinates are distinct. Furthermore, since
 $\|v-0\|_{2}^2 = 8\kappa$
we know from Lemma 7.1, with
$\|v-0\|_{2}^2 = 8\kappa$
we know from Lemma 7.1, with
 $\kappa ' = 8\kappa$
, that for any pair
$\kappa ' = 8\kappa$
, that for any pair
 $(\underline {\psi },\overline {\psi }) \in \Xi _{\beta }(\iota ^2_n, \Phi _n^2)$
, we have
$(\underline {\psi },\overline {\psi }) \in \Xi _{\beta }(\iota ^2_n, \Phi _n^2)$
, we have
 $F_{\iota _{n}^{2},\beta } (\underline {\psi },\overline {\psi }) \leq 4\beta \sqrt {2N\kappa } \lt \kappa$
, where the last inequality follows from the fact that
$F_{\iota _{n}^{2},\beta } (\underline {\psi },\overline {\psi }) \leq 4\beta \sqrt {2N\kappa } \lt \kappa$
, where the last inequality follows from the fact that
 $\beta \lt \sqrt {\kappa }/(4\sqrt {2N})$
.
$\beta \lt \sqrt {\kappa }/(4\sqrt {2N})$
.
It remains to show that
 \begin{align} d_{\mathcal{M}'} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) = \max \left \{ \sup _{y \in \mathcal{F}_{\Omega }} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in \mathcal{F}_{\Omega }} \| \underline {\phi }(y)-\underline {\psi }(y) \|_2^2 \right \} \geq \kappa \end{align}
\begin{align} d_{\mathcal{M}'} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) = \max \left \{ \sup _{y \in \mathcal{F}_{\Omega }} \| \overline {\phi }(y) - \overline {\psi }(y) \|_2^2, \sup _{y \in \mathcal{F}_{\Omega }} \| \underline {\phi }(y)-\underline {\psi }(y) \|_2^2 \right \} \geq \kappa \end{align}
for all
 $(\underline {\phi },\overline {\phi }) \in S^1$
and
$(\underline {\phi },\overline {\phi }) \in S^1$
and
 $(\underline {\psi },\overline {\psi }) \in S^2$
. Assume for a contradiction that this is not the case. By the above argumentation, we know that
$(\underline {\psi },\overline {\psi }) \in S^2$
. Assume for a contradiction that this is not the case. By the above argumentation, we know that
 $\underline {\phi }(0) = \overline {\phi }(0) = 0$
and by the assumption that
$\underline {\phi }(0) = \overline {\phi }(0) = 0$
and by the assumption that
 $d_{\mathcal{M}'} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) \lt \kappa$
we get that
$d_{\mathcal{M}'} ((\underline {\phi },\overline {\phi }),(\underline {\psi },\overline {\psi })) \lt \kappa$
we get that
 $\|\overline {\psi }(0) - 0\|_2^2 = \| \overline {\psi }(0) - \overline {\phi }(0)\|_2^2 \lt \kappa$
, and similarly we get that
$\|\overline {\psi }(0) - 0\|_2^2 = \| \overline {\psi }(0) - \overline {\phi }(0)\|_2^2 \lt \kappa$
, and similarly we get that
 $\|\underline {\psi }(0) - 0 \|_2^2 = \| \underline {\psi }(0) - \underline {\phi }(0)\|_2^2 \lt \kappa$
. Next, we observe that
$\|\underline {\psi }(0) - 0 \|_2^2 = \| \underline {\psi }(0) - \underline {\phi }(0)\|_2^2 \lt \kappa$
. Next, we observe that
 \begin{align*} F_{\iota _{n}^{2},\beta }(\underline {\psi },\overline {\psi }) &\geq \|\max \{v - \overline {\psi }(0),0\} \|_2^2 + \| \max \{\underline {\psi }(0) - v, 0\}\|_2^2 \\ &= \| \max \{v - 0 + \overline {\phi }(0) - \overline {\psi }(0), 0\} \|_2^2 + \| \max \{\underline {\psi }(0) - \underline {\phi }(0) + 0 - v , 0\} \|_2^2 \geq 2\kappa \end{align*}
\begin{align*} F_{\iota _{n}^{2},\beta }(\underline {\psi },\overline {\psi }) &\geq \|\max \{v - \overline {\psi }(0),0\} \|_2^2 + \| \max \{\underline {\psi }(0) - v, 0\}\|_2^2 \\ &= \| \max \{v - 0 + \overline {\phi }(0) - \overline {\psi }(0), 0\} \|_2^2 + \| \max \{\underline {\psi }(0) - \underline {\phi }(0) + 0 - v , 0\} \|_2^2 \geq 2\kappa \end{align*}
where the last inequality follows from Lemma 7.2, with
 $\kappa ' = 4\kappa$
,
$\kappa ' = 4\kappa$
,
 $c = 1/2$
,
$c = 1/2$
,
 $b^1 = \overline {\phi }(0) - \overline {\psi }(0)$
,
$b^1 = \overline {\phi }(0) - \overline {\psi }(0)$
,
 $b^2 = \underline {\phi }(0) - \underline {\psi }(0)$
and
$b^2 = \underline {\phi }(0) - \underline {\psi }(0)$
and
 $a = v - 0$
. However, this is a contradiction, as we know from the above discussion that
$a = v - 0$
. However, this is a contradiction, as we know from the above discussion that
 $F_{\iota _{n}^{2},\beta }(\underline {\psi },\overline {\psi }) \lt \kappa$
. This establishes (7.7) and thereby also (A).
$F_{\iota _{n}^{2},\beta }(\underline {\psi },\overline {\psi }) \lt \kappa$
. This establishes (7.7) and thereby also (A).
To establish items (b)–(d), we see that it is sufficient to establish (b) with
 $c_k = f(\iota ^2_n,\Phi _n^2)$
for any
$c_k = f(\iota ^2_n,\Phi _n^2)$
for any
 $n \in \mathbb{N}$
, since
$n \in \mathbb{N}$
, since
 $\iota _{n}^{2}$
is constant for all
$\iota _{n}^{2}$
is constant for all
 $n\in \mathbb{N}$
. We notice that, for each
$n\in \mathbb{N}$
. We notice that, for each
 $n \in \mathbb{N}$
, we have that
$n \in \mathbb{N}$
, we have that
 $\Phi _n^1 = \Phi _n^2$
, and the elements in
$\Phi _n^1 = \Phi _n^2$
, and the elements in
 $\mathcal{T}_b$
and
$\mathcal{T}_b$
and
 $(0,0)$
coincide in
$(0,0)$
coincide in
 $\iota _n^1$
and
$\iota _n^1$
and
 $\iota _n^2$
and are listed on the same index. Moreover, we have that
$\iota _n^2$
and are listed on the same index. Moreover, we have that
 $(x^{(\ell )}, A(x^{(\ell )})) = ({v} \!+ \! \frac {1}{4^n}e,A({v} \!+ \! \frac {1}{4^n}e)) \in \iota _n^1$
and
$(x^{(\ell )}, A(x^{(\ell )})) = ({v} \!+ \! \frac {1}{4^n}e,A({v} \!+ \! \frac {1}{4^n}e)) \in \iota _n^1$
and
 $(x^{(\ell )}, A(x^{(\ell )})) = ({v},0) \in \iota _n^2$
; thus, we only need to show that the criteria in part (b), for
$(x^{(\ell )}, A(x^{(\ell )})) = ({v},0) \in \iota _n^2$
; thus, we only need to show that the criteria in part (b), for
 $f_{x,i}^{\ell }$
and
$f_{x,i}^{\ell }$
and
 $f_{y,j}^{\ell }$
where
$f_{y,j}^{\ell }$
where
 $i=1,\ldots ,N$
,
$i=1,\ldots ,N$
,
 $j = 1,\ldots ,m$
. We start by
$j = 1,\ldots ,m$
. We start by
 $f_{y,j}^{\ell }$
. For each
$f_{y,j}^{\ell }$
. For each
 $j$
, we have that
$j$
, we have that
 $ |f_{y,j}^{\ell }(\iota _n^1)-f_{y,j}^{\ell }(\iota _n^2)| \! = \! |A(\frac {1}{4^n} e)_j \! - 0| = \frac {1}{4^n}|A(e)_j| \leq \frac {1}{4^n}.$
A similar calculation show the result for
$ |f_{y,j}^{\ell }(\iota _n^1)-f_{y,j}^{\ell }(\iota _n^2)| \! = \! |A(\frac {1}{4^n} e)_j \! - 0| = \frac {1}{4^n}|A(e)_j| \leq \frac {1}{4^n}.$
A similar calculation show the result for
 $f_{x,i}^{\ell }$
, but we omit the details. This establishes (b)–(d) above and concludes the proof.
$f_{x,i}^{\ell }$
, but we omit the details. This establishes (b)–(d) above and concludes the proof.
7.3. Proof of theorem 6.8
Proof of Theorem 6.8. By Proposition 7.6, and the definition of the breakdown epsilons
 $\epsilon _{\mathrm{B}}^s$
and
$\epsilon _{\mathrm{B}}^s$
and
 $\epsilon _{\mathbb{P}\mathrm{B}}^s(p)$
, it follows that there exists a set
$\epsilon _{\mathbb{P}\mathrm{B}}^s(p)$
, it follows that there exists a set
 $\hat {\Lambda } \in \mathcal{L}^1(\Lambda )$
, giving
$\hat {\Lambda } \in \mathcal{L}^1(\Lambda )$
, giving
 $\Delta _1$
-information for
$\Delta _1$
-information for
 $\{\Xi _{\beta },\Omega ,{\mathcal{M}}',\Lambda \}$
, such that, for any algorithm
$\{\Xi _{\beta },\Omega ,{\mathcal{M}}',\Lambda \}$
, such that, for any algorithm
 $\Gamma \,:\, \hat \Omega \to {\mathcal{M}}'$
, there exists a pair
$\Gamma \,:\, \hat \Omega \to {\mathcal{M}}'$
, there exists a pair
 $({\mathcal{T}}_1, \theta _{\Phi }^1) \in \Omega$
such that
$({\mathcal{T}}_1, \theta _{\Phi }^1) \in \Omega$
such that
 $\text{dist}_{\mathcal{M}'} (\Xi _{\beta }({\mathcal{T}}_1, \theta _{\Phi }^1),\Gamma ({\mathcal{T}}_1, \theta _{\Phi }^1)) \geq \kappa /2$
, and that, for any randomised algorithm
$\text{dist}_{\mathcal{M}'} (\Xi _{\beta }({\mathcal{T}}_1, \theta _{\Phi }^1),\Gamma ({\mathcal{T}}_1, \theta _{\Phi }^1)) \geq \kappa /2$
, and that, for any randomised algorithm
 $\Gamma ^{ran} \,:\, \hat \Omega \to {\mathcal{M}}$
, there exists a pair
$\Gamma ^{ran} \,:\, \hat \Omega \to {\mathcal{M}}$
, there exists a pair
 $({\mathcal{T}}_2, \theta _{\Phi }^2) \in \Omega$
such that
$({\mathcal{T}}_2, \theta _{\Phi }^2) \in \Omega$
such that
 $\mathbb{P}(\text{dist}_{\mathcal{M}'}(\Xi _{\beta }({\mathcal{T}}_2, \theta _{\Phi }^2),\Gamma ({\mathcal{T}}_2, \theta _{\Phi }^2)) \geq \kappa /2) \geq 1/2$
. The statement of Theorem 6.8 follows from this.
$\mathbb{P}(\text{dist}_{\mathcal{M}'}(\Xi _{\beta }({\mathcal{T}}_2, \theta _{\Phi }^2),\Gamma ({\mathcal{T}}_2, \theta _{\Phi }^2)) \geq \kappa /2) \geq 1/2$
. The statement of Theorem 6.8 follows from this.
Financial support
LG acknowledges support from the Niels Henrik Abel and C. M. Guldbergs memorial fund. ACH acknowledges support from the Simons Foundation Award No. 663281 granted to the Institute of Mathematics of the Polish Academy of Sciences for the years 2021–2023, from a Royal Society University Research Fellowship, and from the Leverhulme Prize 2017.
Competing interest
The authors declare no competing interests.
Appendix A. ReLU networks satisfy Assumption 2.1
In this appendix, we present a proposition that illustrates that Assumption 2.1 is satisfied by any class of ReLU networks, with input dimension
 $m$
and output dimension
$m$
and output dimension
 $N$
, of fixed depth greater than or equal to 2. We start by showing a lemma that asserts that Assumption 2.1 is satisfied for ReLU networks of depth equal to 2 with output dimension
$N$
, of fixed depth greater than or equal to 2. We start by showing a lemma that asserts that Assumption 2.1 is satisfied for ReLU networks of depth equal to 2 with output dimension
 $N=1$
. We then assert the general result by a corollary.
$N=1$
. We then assert the general result by a corollary.
We start by introducing the following notation: For a vector
 $z \subseteq {\mathbb{R}}^m$
,
$z \subseteq {\mathbb{R}}^m$
,
 $\pi _1(z)$
is the projection onto the first coordinate defined as:
$\pi _1(z)$
is the projection onto the first coordinate defined as:
 \begin{equation} \begin{split} \pi _1(z) &\,:\!=\, \{ z_1 \: | \: z = (z_1, \ldots , z_m) \in {\mathbb{R}}^m \}, \end{split} \end{equation}
\begin{equation} \begin{split} \pi _1(z) &\,:\!=\, \{ z_1 \: | \: z = (z_1, \ldots , z_m) \in {\mathbb{R}}^m \}, \end{split} \end{equation}
We repeat the definition of a neural network and Assumption 2.1 for completeness.
Definition A.1. Let
 $K$
be a natural number and let
$K$
be a natural number and let
 $\mathbf{N} \,:\!=\, (N_0, N_{1}, \ldots ,N_{K-1}, N_K) \in \mathbb{N}^{K+1}$
. A neural network with dimension
$\mathbf{N} \,:\!=\, (N_0, N_{1}, \ldots ,N_{K-1}, N_K) \in \mathbb{N}^{K+1}$
. A neural network with dimension
 $(\mathbf{N},K)$
is a map
$(\mathbf{N},K)$
is a map
 $\Phi \,:\, {\mathbb{R}}^{N_0} \to {\mathbb{R}}^{N_K}$
such that
$\Phi \,:\, {\mathbb{R}}^{N_0} \to {\mathbb{R}}^{N_K}$
such that
 \begin{align*} \Phi (x) \,:\!=\, V^{(K)} \circ \sigma \circ V^{(K-1)} \circ \sigma \circ V^{(K-2)} \circ \cdots \circ \sigma \circ V^{(1)}x, \end{align*}
\begin{align*} \Phi (x) \,:\!=\, V^{(K)} \circ \sigma \circ V^{(K-1)} \circ \sigma \circ V^{(K-2)} \circ \cdots \circ \sigma \circ V^{(1)}x, \end{align*}
where, for
 $k = 1, \ldots , K$
, the map
$k = 1, \ldots , K$
, the map
 $V^{(k)}$
is an affine map from
$V^{(k)}$
is an affine map from
 ${\mathbb{R}}^{N_{k-1}} \to {\mathbb{R}}^{N_k}$
, that is
${\mathbb{R}}^{N_{k-1}} \to {\mathbb{R}}^{N_k}$
, that is
 $V^{(k)} x^{(k)} = W^{(k)}x^{(k)} + b^{(k)}$
, where
$V^{(k)} x^{(k)} = W^{(k)}x^{(k)} + b^{(k)}$
, where
 $b^{(k)} \in {\mathbb{R}}^{N_k}$
and
$b^{(k)} \in {\mathbb{R}}^{N_k}$
and
 $W^{(k)} \in {\mathbb{R}}^{N_{k-1} \times N_k}$
. The map
$W^{(k)} \in {\mathbb{R}}^{N_{k-1} \times N_k}$
. The map
 $\sigma \,:\, {\mathbb{R}} \to {\mathbb{R}}$
is interpreted as a coordinatewise map and is called the non-linearity or activation function.
$\sigma \,:\, {\mathbb{R}} \to {\mathbb{R}}$
is interpreted as a coordinatewise map and is called the non-linearity or activation function.
Assumption 2.1. For a given integer
 $\ell \geq 1$
, we assume that
$\ell \geq 1$
, we assume that
 $\mathcal{NN}_{\ell }$
is a class of neural networks such that for any collection
$\mathcal{NN}_{\ell }$
is a class of neural networks such that for any collection
 $\mathcal{T} = \left \{(x^{(1)}, y^{(1)}), \ldots , (x^{(\ell )}, y^{(\ell )})\right \}\subset {\mathbb{R}}^{N} \times {\mathbb{R}}^m$
, where each
$\mathcal{T} = \left \{(x^{(1)}, y^{(1)}), \ldots , (x^{(\ell )}, y^{(\ell )})\right \}\subset {\mathbb{R}}^{N} \times {\mathbb{R}}^m$
, where each
 $y$
-coordinate is distinct, the following holds:
$y$
-coordinate is distinct, the following holds:
-
(i) (
$\ell$
-interpolatory): There exists a neural network
$\Psi \in \mathcal{NN}_{\ell }$
, such that
$\Psi (y) = x$
for each
$(x,y)\in \mathcal{T}$
. -
(ii) For any choice of
$x' \in {\mathbb{R}}^{N}$
, any
$k \in \{1,\ldots ,\ell \}$
and any
$\Psi \in \mathcal{NN}_{\ell }$
satisfying (i), there exist neural networks
$\underline {\phi },\overline {\phi } \in \mathcal{NN}_{\ell }$
, such that








-
(a)
$\underline {\phi }(y) \leq \Psi (y) \leq \overline {\phi }(y)$
for all
$y \in {\mathbb{R}}^m$
, and -
(b) such that
$\underline {\phi }(y) = \overline {\phi }(y) = x$
for all
$(x,y)\in \mathcal{T}\setminus \{ x^{(k)},y^{(k)}\}$
, and -
(c)
$\underline {\phi }(y^{(k)}) = \min \{x',x^{(k)}\}$
and
$\overline {\phi }(y^{(k)}) = \max \{x',x^{(k)}\}$
.






Lemma A.2. Let
 $m \in \mathbb{N}$
and let
$m \in \mathbb{N}$
and let
 $N =1$
. Let
$N =1$
. Let
 ${\mathcal{N} \mathcal{N}}_{\mathrm{ReLU}}^2$
denote the class of neural networks, according to Definition A.1
, where
${\mathcal{N} \mathcal{N}}_{\mathrm{ReLU}}^2$
denote the class of neural networks, according to Definition A.1
, where
 $K = 2$
,
$K = 2$
,
 $N_0 = m$
,
$N_0 = m$
,
 $N_1 \in \mathbb{N}$
and
$N_1 \in \mathbb{N}$
and
 $N_2 = N = 1$
, and where
$N_2 = N = 1$
, and where
 $\sigma \,:\, {\mathbb{R}} \to {\mathbb{R}}$
is given by
$\sigma \,:\, {\mathbb{R}} \to {\mathbb{R}}$
is given by
 \begin{align*} \sigma (y) = \mathrm{ReLU}(y) = \max \{y,0\}. \end{align*}
\begin{align*} \sigma (y) = \mathrm{ReLU}(y) = \max \{y,0\}. \end{align*}
Then
 ${\mathcal{N} \mathcal{N}}_{\mathrm{ReLU}}^2$
satisfies Assumption 2.1
.
${\mathcal{N} \mathcal{N}}_{\mathrm{ReLU}}^2$
satisfies Assumption 2.1
.
Proof. Let
 $\ell \in \mathbb{N}$
and let
$\ell \in \mathbb{N}$
and let
 ${\mathcal{T}} \subset {\mathbb{R}} \times {\mathbb{R}}^m$
be as described in Assumption 2.1. More precisely,
${\mathcal{T}} \subset {\mathbb{R}} \times {\mathbb{R}}^m$
be as described in Assumption 2.1. More precisely,
 \begin{equation*} \mathcal{T} = \left \{(x^{(1)}, y^{(1)}), \ldots , (x^{(\ell )}, y^{(\ell )})\right \}\subset {\mathbb{R}} \times {\mathbb{R}}^m, \end{equation*}
\begin{equation*} \mathcal{T} = \left \{(x^{(1)}, y^{(1)}), \ldots , (x^{(\ell )}, y^{(\ell )})\right \}\subset {\mathbb{R}} \times {\mathbb{R}}^m, \end{equation*}
where each
 $y$
-coordinate is distinct. We proceed by showing that there exists three neural networks
$y$
-coordinate is distinct. We proceed by showing that there exists three neural networks
 $\Phi ,\underline {\phi }, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\text{ReLU}}^2$
that satisfy points
$\Phi ,\underline {\phi }, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\text{ReLU}}^2$
that satisfy points
 $(i)$
and
$(i)$
and
 $(ii)$
in Assumption 2.1. Indeed, let
$(ii)$
in Assumption 2.1. Indeed, let
 $k \in \{1, \ldots , \ell \}$
and let
$k \in \{1, \ldots , \ell \}$
and let
 $x' \in {\mathbb{R}}$
. Set
$x' \in {\mathbb{R}}$
. Set
 $x^{(k),1} = \min \{x',x^{(k)}\}$
and
$x^{(k),1} = \min \{x',x^{(k)}\}$
and
 $x^{(k),2} = \max \{x',x^{(k)}\}$
. We then construct neural networks
$x^{(k),2} = \max \{x',x^{(k)}\}$
. We then construct neural networks
 $\Phi ,\underline {\phi }, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\text{ReLU}}^2$
such that
$\Phi ,\underline {\phi }, \overline {\phi } \in {\mathcal{N} \mathcal{N}}_{\text{ReLU}}^2$
such that
-
•
$\Phi$
interpolates the points
$\{(y^{(i)},x^{(i)})\}_{i = 1}^{\ell }$
, -
•
$\underline {\phi }$
interpolates the points
$\{(y^{(k)},x^{(k),1})\} \cup [\{(y^{(i)},x^{(i)})\}_{i = 1}^{\ell -1} {\backslash } \{(y^{(k)},x^{(k)})\}]$
, -
•
$\overline {\phi }$
interpolates the points
$\{(y^{(k)},x^{(k),2})\} \cup [\{(y^{(i)},x^{(i)})\}_{i = 1}^{\ell -1} {\backslash } \{(y^{(k)},x^{(k)})\}]$
,






and such that
 $\underline {\phi }(y) \leq \Phi (y) \leq \overline {\phi }(y)$
for all
$\underline {\phi }(y) \leq \Phi (y) \leq \overline {\phi }(y)$
for all
 $y \in {\mathbb{R}}^m$
.
$y \in {\mathbb{R}}^m$
.
Let
 $\pi _1(y^{(i)}) = y^{(i)}_1$
be the projection onto the first coordinate of the vector
$\pi _1(y^{(i)}) = y^{(i)}_1$
be the projection onto the first coordinate of the vector
 $y^{(i)} \in {\mathbb{R}}^m$
. We may assume without loss of generality that the points in
$y^{(i)} \in {\mathbb{R}}^m$
. We may assume without loss of generality that the points in
 $\mathcal{T}$
are ordered such that
$\mathcal{T}$
are ordered such that
 $y^{(1)}_1 \leq y^{(2)}_1 \leq \ldots , \leq y^{(\ell )}_1$
. Moreover, if
$y^{(1)}_1 \leq y^{(2)}_1 \leq \ldots , \leq y^{(\ell )}_1$
. Moreover, if
 $y^{(i)}_1 = y^{(i+1)}_1$
for some
$y^{(i)}_1 = y^{(i+1)}_1$
for some
 $i \in \{1, \ldots , \ell \}$
, we may remove
$i \in \{1, \ldots , \ell \}$
, we may remove
 $y^{(i+1)}_1$
from the list; thereby, we may assume without loss of generality that
$y^{(i+1)}_1$
from the list; thereby, we may assume without loss of generality that
 $y^{(1)}_1 \lt y^{(2)}_1 \lt \ldots , \lt y^{(\ell )}_1$
. We then construct piecewise linear functions
$y^{(1)}_1 \lt y^{(2)}_1 \lt \ldots , \lt y^{(\ell )}_1$
. We then construct piecewise linear functions
 $f\,:\, {\mathbb{R}} \to {\mathbb{R}}, \underline {f}\,:\, {\mathbb{R}} \to {\mathbb{R}}$
, and
$f\,:\, {\mathbb{R}} \to {\mathbb{R}}, \underline {f}\,:\, {\mathbb{R}} \to {\mathbb{R}}$
, and
 $\overline {f}\,:\, {\mathbb{R}} \to {\mathbb{R}}$
such that
$\overline {f}\,:\, {\mathbb{R}} \to {\mathbb{R}}$
such that
-
•
$f$
interpolates the points
$\{(y_1^{(i)},x^{(i)})\}_{i = 1}^{\ell }$
, -
•
$\underline {f}$
interpolates the points
$\{(y_1^{(k)},x^{(k),1})\} \cup [\{(y_1^{(i)},x^{(i)})\}_{i = 1}^{\ell -1} {\backslash } \{(y_1^{(k)},x^{(k)})\}]$
, -
•
$\overline {f}$
interpolates the points
$\{(y_1^{(k)},x^{(k),2})\} \cup [\{(y_1^{(i)},x^{(i)})\}_{i = 1}^{\ell -1} {\backslash } \{(y_1^{(k)},x^{(k)})\}]$
.






Indeed, let
 $\underline {f}\,:\, {\mathbb{R}} \to {\mathbb{R}}$
, and
$\underline {f}\,:\, {\mathbb{R}} \to {\mathbb{R}}$
, and
 $\overline {f} \,:\, {\mathbb{R}} \to {\mathbb{R}}$
be given by
$\overline {f} \,:\, {\mathbb{R}} \to {\mathbb{R}}$
be given by
 \begin{align*} &\underline {f}(y) = \begin{cases} \frac {x^{(i+1)} - x^{(i)}}{y_1^{(i+1)}-y_1^{(i)}}(y - y_1^{(i)}) + x^{(i)} \quad \text{when} \; y \in [y_1^{(i)},y_1^{(i+1)}) \: \text{and} \: i \neq k, i \neq k+1 \\[8pt] \frac {x^{(k),1} - x^{(k-1)}}{y_1^{(k)}-y_1^{(k-1)}}(y - y_1^{(k-1)}) + x^{(k-1)} \quad \text{when} \; y \in [y_1^{(k-1)},y_1^{(k)}) \\[8pt] \frac {x^{(k+1)} - x^{(k),1}}{y_1^{(k+1)}-y_1^{(k)}}(y - y_1^{(k)}) + x^{(k),1} \quad \text{when} \; y \in [y_1^{(k)},y_1^{(k+1)}), \end{cases} \quad \text{and} \quad \\[2pt] &\overline {f}(y) = \begin{cases} \frac {x^{(i+1)} - x^{(i)}}{y_1^{(i+1)}-y_1^{(i)}}(y - y_1^{(i)}) + x^{(i)} \quad \text{when} \; y \in [y_1^{(i)},y_1^{(i+1)}) \: \text{and} \: i \neq k, i \neq k+1 \\[8pt] \frac {x^{(k),2} - x^{(k-1)}}{y_1^{(k)}-y_1^{(k-1)}}(y - y_1^{(k-1)}) + x^{(k-1)} \quad \text{when} \; y \in [y_1^{(k-1)},y_1^{(k)}) \\[8pt] \frac {x^{(k+1)} - x^{(k),2}}{y_1^{(k+1)}-y_1^{(k)}}(y - y_1^{(k)}) + x^{(k),2} \quad \text{when} \; y \in [y_1^{(k)},y_1^{(k+1)}), \end{cases} \end{align*}
\begin{align*} &\underline {f}(y) = \begin{cases} \frac {x^{(i+1)} - x^{(i)}}{y_1^{(i+1)}-y_1^{(i)}}(y - y_1^{(i)}) + x^{(i)} \quad \text{when} \; y \in [y_1^{(i)},y_1^{(i+1)}) \: \text{and} \: i \neq k, i \neq k+1 \\[8pt] \frac {x^{(k),1} - x^{(k-1)}}{y_1^{(k)}-y_1^{(k-1)}}(y - y_1^{(k-1)}) + x^{(k-1)} \quad \text{when} \; y \in [y_1^{(k-1)},y_1^{(k)}) \\[8pt] \frac {x^{(k+1)} - x^{(k),1}}{y_1^{(k+1)}-y_1^{(k)}}(y - y_1^{(k)}) + x^{(k),1} \quad \text{when} \; y \in [y_1^{(k)},y_1^{(k+1)}), \end{cases} \quad \text{and} \quad \\[2pt] &\overline {f}(y) = \begin{cases} \frac {x^{(i+1)} - x^{(i)}}{y_1^{(i+1)}-y_1^{(i)}}(y - y_1^{(i)}) + x^{(i)} \quad \text{when} \; y \in [y_1^{(i)},y_1^{(i+1)}) \: \text{and} \: i \neq k, i \neq k+1 \\[8pt] \frac {x^{(k),2} - x^{(k-1)}}{y_1^{(k)}-y_1^{(k-1)}}(y - y_1^{(k-1)}) + x^{(k-1)} \quad \text{when} \; y \in [y_1^{(k-1)},y_1^{(k)}) \\[8pt] \frac {x^{(k+1)} - x^{(k),2}}{y_1^{(k+1)}-y_1^{(k)}}(y - y_1^{(k)}) + x^{(k),2} \quad \text{when} \; y \in [y_1^{(k)},y_1^{(k+1)}), \end{cases} \end{align*}
and let
 $f\,:\, {\mathbb{R}} \to {\mathbb{R}}$
be given by
$f\,:\, {\mathbb{R}} \to {\mathbb{R}}$
be given by
 $f(y) = \frac {x^{(i+1)} - x^{(i)}}{y_1^{(i+1)}-y_1^{(i)}}(y - y_1^{(i)}) + x^{(i)} \; \text{when} \; y \in [y_1^{(i)},y_1^{(i+1)}]$
. It is then straightforward to check that
$f(y) = \frac {x^{(i+1)} - x^{(i)}}{y_1^{(i+1)}-y_1^{(i)}}(y - y_1^{(i)}) + x^{(i)} \; \text{when} \; y \in [y_1^{(i)},y_1^{(i+1)}]$
. It is then straightforward to check that
 $f,\underline {f}$
and
$f,\underline {f}$
and
 $\overline {f}$
are piecewise linear functions such that
$\overline {f}$
are piecewise linear functions such that
 $\underline {f}(y) \leq f(y) \leq \overline {f}(y)$
for all
$\underline {f}(y) \leq f(y) \leq \overline {f}(y)$
for all
 $y \in {\mathbb{R}}$
and such that they interpolate the desired points. By [Reference Arora, Basu, Mianjy and Mukherjee6, Theorem 2.2], every such function can be represented by a two-layer ReLU network. More precisely, we have that
$y \in {\mathbb{R}}$
and such that they interpolate the desired points. By [Reference Arora, Basu, Mianjy and Mukherjee6, Theorem 2.2], every such function can be represented by a two-layer ReLU network. More precisely, we have that
 $f = V^{(2)} \circ \sigma \circ V^{(1)}$
,
$f = V^{(2)} \circ \sigma \circ V^{(1)}$
,
 $\underline {f} = \underline {V}^{(2)} \circ \sigma \circ \underline {V}^{(1)}$
, and
$\underline {f} = \underline {V}^{(2)} \circ \sigma \circ \underline {V}^{(1)}$
, and
 $\overline {f} = \overline {V}^{(2)} \circ \sigma \circ \overline {V}^{(1)}$
. Finally, the projection
$\overline {f} = \overline {V}^{(2)} \circ \sigma \circ \overline {V}^{(1)}$
. Finally, the projection
 $\pi _1 \,:\, {\mathbb{R}}^m \to {\mathbb{R}}$
onto the first coordinate is a linear map. Hence, we may set
$\pi _1 \,:\, {\mathbb{R}}^m \to {\mathbb{R}}$
onto the first coordinate is a linear map. Hence, we may set
 $\Phi (y) = V^{(2)} \circ \sigma \circ V^{(1)} \circ \pi _1(y)$
,
$\Phi (y) = V^{(2)} \circ \sigma \circ V^{(1)} \circ \pi _1(y)$
,
 $\underline {\phi }(y) = \underline {V}^{(2)} \circ \sigma \circ \underline {V}^{(1)} \circ \pi _1(y)$
and
$\underline {\phi }(y) = \underline {V}^{(2)} \circ \sigma \circ \underline {V}^{(1)} \circ \pi _1(y)$
and
 $\overline {\phi }(y) = \overline {V}^{(2)} \circ \sigma \circ \overline {V}^{(1)} \circ \pi _1(y)$
to obtain the desired result.
$\overline {\phi }(y) = \overline {V}^{(2)} \circ \sigma \circ \overline {V}^{(1)} \circ \pi _1(y)$
to obtain the desired result.
Corollary A.3. Let
 $m,N,d \in \mathbb{N}$
with
$m,N,d \in \mathbb{N}$
with
 $d \geq 2$
. Let
$d \geq 2$
. Let
 ${\mathcal{N} \mathcal{N}}_{\mathrm{ReLU}}^d$
denote the class of neural networks, according to Definition A.1
, where
${\mathcal{N} \mathcal{N}}_{\mathrm{ReLU}}^d$
denote the class of neural networks, according to Definition A.1
, where
 $K = d$
,
$K = d$
,
 $N_0 = m$
,
$N_0 = m$
,
 $N_1, \ldots , N_{d-1} \in \mathbb{N}$
and
$N_1, \ldots , N_{d-1} \in \mathbb{N}$
and
 $N_d = N$
, and where
$N_d = N$
, and where
 $\sigma \,:\, {\mathbb{R}} \to {\mathbb{R}}$
is given by
$\sigma \,:\, {\mathbb{R}} \to {\mathbb{R}}$
is given by
 \begin{align*} \sigma (y) = \mathrm{ReLU}(y) = \max \{y,0\}. \end{align*}
\begin{align*} \sigma (y) = \mathrm{ReLU}(y) = \max \{y,0\}. \end{align*}
Then
 ${\mathcal{N} \mathcal{N}}_{\mathrm{ReLU}}^d$
satisfies Assumption 2.1
.
${\mathcal{N} \mathcal{N}}_{\mathrm{ReLU}}^d$
satisfies Assumption 2.1
.
Proof. To assert the statement in the corollary from Lemma A.2, it suffices to prove the following two statements:
-
(1) Given a
$d$
-layer neural network
$\Phi \,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N$
, it is possible to add a ReLU layer, without changing the output, to obtain a
$d+1$
-layer neural network. -
(2) Given
$x \in {\mathbb{R}}^N$
,
$y \in {\mathbb{R}}^m$
and
$d$
-layer neural networks
$\Phi _1, \ldots , \Phi _N$
such that
$\Phi _i(y) = x_i$
for
$i = 1, \ldots , N$
, we can construct a
$d$
-layer neural network
$\Phi \,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N$
such that
$\Phi (y) =x$
.












We start by proving
 $(i)$
: We observe that, with
$(i)$
: We observe that, with
 $\sigma =$
ReLU, we have that
$\sigma =$
ReLU, we have that
 $x = \sigma (x) - \sigma (-x)$
. Hence, by setting
$x = \sigma (x) - \sigma (-x)$
. Hence, by setting
 $V^{(1)} = [I_N, -I_N]^T$
, where
$V^{(1)} = [I_N, -I_N]^T$
, where
 $I_N$
denotes the
$I_N$
denotes the
 $N$
-dimensional identity matrix, and
$N$
-dimensional identity matrix, and
 $V^{(2)} = [I_N, -I_N]$
, we get that
$V^{(2)} = [I_N, -I_N]$
, we get that
 $V^{(2)} \circ \sigma \circ V^{(1)}(x) = \sigma (x) - \sigma (-x) = x$
for any
$V^{(2)} \circ \sigma \circ V^{(1)}(x) = \sigma (x) - \sigma (-x) = x$
for any
 $x \in {\mathbb{R}}^N$
. Thus, let
$x \in {\mathbb{R}}^N$
. Thus, let
 $\Phi \,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N$
be an arbitrary
$\Phi \,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N$
be an arbitrary
 $d$
-layer neural network, then the composition
$d$
-layer neural network, then the composition
 $V^{(2)} \circ \sigma \circ V^{(1)} \circ \Phi (x) = \Phi (x)$
is a
$V^{(2)} \circ \sigma \circ V^{(1)} \circ \Phi (x) = \Phi (x)$
is a
 $d+1$
-layer neural network with the same output as
$d+1$
-layer neural network with the same output as
 $\Phi$
. This asserts part
$\Phi$
. This asserts part
 $(i)$
.
$(i)$
.
We now prove part
 $(ii)$
: Let
$(ii)$
: Let
 $x = (x_1, \ldots , x_N) \in {\mathbb{R}}^N$
be an arbitrary vector and assume that for a given
$x = (x_1, \ldots , x_N) \in {\mathbb{R}}^N$
be an arbitrary vector and assume that for a given
 $y \in {\mathbb{R}}^m$
there exists
$y \in {\mathbb{R}}^m$
there exists
 $d$
-layer neural networks
$d$
-layer neural networks
 $\Phi _1, \ldots , \Phi _N \,:\, {\mathbb{R}}^N \to {\mathbb{R}}$
such that
$\Phi _1, \ldots , \Phi _N \,:\, {\mathbb{R}}^N \to {\mathbb{R}}$
such that
 $\Phi _i(y) = x_i$
for each
$\Phi _i(y) = x_i$
for each
 $i = 1, \ldots , N$
. We can then ‘stack’ the neural networks
$i = 1, \ldots , N$
. We can then ‘stack’ the neural networks
 $\Phi _1, \ldots , \Phi _N$
to construct a neural network
$\Phi _1, \ldots , \Phi _N$
to construct a neural network
 $\Phi \,:\, {\mathbb{R}}^N \to {\mathbb{R}}^m$
such that
$\Phi \,:\, {\mathbb{R}}^N \to {\mathbb{R}}^m$
such that
 $\Phi (y) = x$
in the following way. Let
$\Phi (y) = x$
in the following way. Let
 $V^{(j)} = [V_1^{(j)}, \ldots , V_N^{(j)}]^T$
for
$V^{(j)} = [V_1^{(j)}, \ldots , V_N^{(j)}]^T$
for
 $j = 1, \ldots , d$
, where
$j = 1, \ldots , d$
, where
 $V_i^{(j)}$
denotes the
$V_i^{(j)}$
denotes the
 $j$
’th affine map in the neural network
$j$
’th affine map in the neural network
 $\Phi _i$
for
$\Phi _i$
for
 $i =1, \ldots , N$
. We then define
$i =1, \ldots , N$
. We then define
 $\Phi \,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N$
to be the neural network
$\Phi \,:\, {\mathbb{R}}^m \to {\mathbb{R}}^N$
to be the neural network
 $\Phi = V^{(d)} \circ \sigma \circ \cdots \circ \sigma \circ V^{(1)}$
, then it is clear that
$\Phi = V^{(d)} \circ \sigma \circ \cdots \circ \sigma \circ V^{(1)}$
, then it is clear that
 $\Phi$
is a
$\Phi$
is a
 $d$
-layer neural network. Moreover,
$d$
-layer neural network. Moreover,
 $\Phi (y) = [\Phi _1(y), \ldots , \Phi _N(y)]^T = (x_1, \ldots , x_N) = x$
, this asserts part
$\Phi (y) = [\Phi _1(y), \ldots , \Phi _N(y)]^T = (x_1, \ldots , x_N) = x$
, this asserts part
 $(ii)$
.
$(ii)$
.






 Open access
Open access